日志
- 分享
Kyuubi详解
-
2022-12-30 08:43
-
2022年12月22日,Apache 软件基金会(ASF)官方宣布 Apache Kyuubi 正式毕业,成为顶级项目(TLP)。 Apache Kyuubi 是一个分布式和多租户网关,用于在数据仓库和湖仓上提供无服务器SQL。 项目最初由网易数帆开发并于2018年开源,2021年6月捐赠 Apache基金会,经过1年多的孵化于2022年11月通过投票,在12月顺利毕业 ...
-
553 次阅读|0 个评论
- 分享
jvm hs_err_pid.log 文件分析工具 CrashAnalysis 使用教程
-
2021-5-13 15:10
-
在上一篇《jvm crash(崩溃)文件 hs_err_pid.log 分析教程》中,我们可以看到 jvm crash 后生成的 hs_err_pid.log 文件非常的复杂,非常的难懂!那么有没有一款工具能帮助我们来分析它呢?且看本文给你推荐的这款工具 CrashAnalysis 的用法。 CrashAnalysis 简介 CrashAnalysis 是一款诊断工具。是某APM项目组成 ...
-
2729 次阅读|0 个评论
- 分享
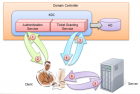
Kerberos身份验证流程
-
2021-1-11 16:48
-
介绍: Kerberos 是一种由 MIT(麻省理工大学)提出的一种网络身份验证协议。它旨在通过使用密钥加密技术为客户端/服务器应用程序提供强身份验证。 在 Kerberos 认证中,最主要的问题是如何证明「你是你」的问题,如当一个 Client 去访问 Server 服务器上的某服务时,Server 如何判断 Client 是否有权限来访问 ...
-
1026 次阅读|0 个评论
- 分享
Hive优化案例
-
2021-1-6 14:41
-
1.Hadoop计算框架的特点 数据量大不是问题,数据倾斜是个问题。 jobs数比较多的作业效率相对比较低,比如即使有几百万的表,如果多次关联多次汇总,产生十几个jobs,耗时很长。原因是map reduce作业初始化的时间是比较长的。 sum,count,max,min等UDAF,不怕数据倾斜问题,hadoop在map端的汇总并优化,使数据倾斜 ...
-
1042 次阅读|0 个评论
- 分享
Spark3.0 preview预览版尝试GPU调用(本地模式不支持GPU)
-
2020-7-16 15:47
-
Spark3.0 preview预览版可以下载使用,地址:https://archive.apache.org/dist/spark/spark-3.0.0-preview/,pom.xml也可以进行引用,如下: dependencies dependency groupIdjunit/groupId & ...
-
996 次阅读|0 个评论
- 分享
java实现向word文档中插入柱状图,并更改颜色
-
2020-5-14 19:28
-
java实现向word文档中插入柱状图,并更改颜色。 将docx转化为xml文件在进行操作 链接: https://pan.baidu.com/s/1432R3wUnu4SIxivcoTVapg 提取码: 9kha
-
1184 次阅读|0 个评论
- 分享
基于spark sql引擎的即席查询服务
-
2020-5-13 17:12
-
English | 简体中文 基于SparkSQL实现了一套即席查询服务,具有如下特性: 优雅的交互方式,支持多种datasource/sink,多数据源混算 spark常驻服务,基于zookeeper的引擎自动发现 负载均衡,多个引擎随机执行 多session模式实现并行查询 采用spark的FAIR调度,避免资源被大任务独占 基于spark的动态资源 ...
-
1005 次阅读|0 个评论
- 分享
shell实现:输入密码不回显
-
2020-5-10 19:03
-
#!/bin/bash #输入密码不回显 function enterPass() { local PASSWORD="" stty -echo #设置输入不回显 read -p "Please input PASSWORD: " PASSWORD echo -e "\r" #换行 stty echo #取消不回显 echo "Entered password is ...
-
791 次阅读|0 个评论
- 分享
Flink Catalog的作用
-
2020-1-12 10:14
-
Catalog:所有对数据库和表的元数据信息都存放再Flink CataLog内部目录结构中,其存放了flink内部所有与Table相关的元数据信息,包括表结构信息/数据源信息等。
-
2624 次阅读|0 个评论
- 分享
Hbase写入优化策略
-
2019-11-19 16:49
-
1 关闭autoflush,批量put 2 检查memstore大小,是不是频繁刷hfile 3 检查JVM,是否有频繁full GC,导致客户端查询卡死 4 检查是否写入的时候频繁compaction(minor compaction或者major compaction) 5 检查表是否存在预定义分区,避免region热点导致不断的split 6 检查版本设置,是否版本太大,导致过期数据太多,查 ...
-
706 次阅读|0 个评论
- 新手帮助
- 新手帮助:注册遇到问题,领取资源,加入铁粉群,不会使用搜索,如何获取积分等
查看 »
 /2
/2 