问题导读 1.什么是最近公共祖先? 2.求任意两个结点的最近公共祖先,这几种解法有什么特点? 前言 https://github.com/julycoding/The-Art-Of-Programming-by-July 。如此,任何人都可以在github上改进本系列,包括指正bug、优化代码、重绘图片、英文翻译等等工作。第三十九章、最近公共祖先LCA问题 题意分析 http://blog.csdn.net/v_july_v/article/details/11921021 ,网上也有很多文章阐述了这个问题,然要么是阐述不够细致规范,要么千篇一律的晦涩难懂,希望本文能把这个问题阐述的明明白白。解法一、暴力对待 1.1、是二叉查找树 //copyright@eriol 2011
//modified by July 2014
public int query(Node t, Node u, Node v) {
int left = u.value;
int right = v.value;
Node parent = null;
//二叉查找树内,如果左结点大于右结点,不对,交换
if (left > right) {
int temp = left;
left = right;
right = temp;
}
while (true) {
//如果t小于u、v,往t的右子树中查找
if (t.value right) {
parent = t;
t = t.left;
} else if (t.value == left || t.value == right) {
return parent.value;
} else {
return t.value;
}
}
} 复制代码 1.2、不是二叉查找树 原文 。//copyright@allantop 2014-1-22-20:01
node* getLCA(node* root, node* node1, node* node2)
{
if(root == null)
return null;
if(root== node1 || root==node2)
return root;
node* left = getLCA(root->left, node1, node2);
node* right = getLCA(root->right, node1, node2);
if(left != null && right != null)
return root;
else if(left != null)
return left;
else if (right != null)
return right;
else
return null;
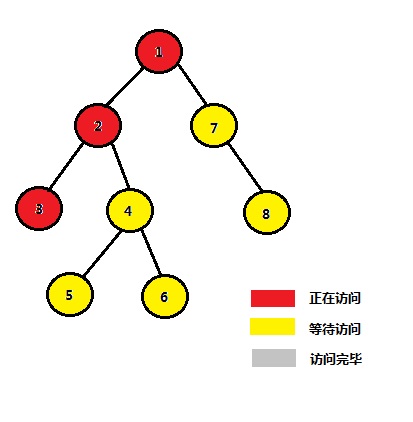
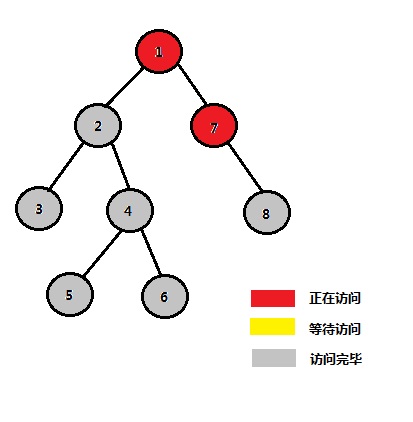
} 复制代码 解法二、Tarjan算法 2.1、什么是Tarjan算法 先创建由u构成的集合,再对u的每颗子树进行搜索,每搜索完一棵子树,这时候子树中所有的结点的最近公共祖先就是u了 。此文 的一个例子,如下图(不同颜色的结点相当于不同的集合): 2.2、Tarjan算法如何而来 “ 如果当前结点t 满足 u “ 如果要求多个任意两个结点的最近公共祖先,则相当于是批量查询” ,即在很多组的询问的情况下,或许可以先确定一个LCA。例如是根节点1,然后再去检查所有询问,看是否满足刚才的定理,不满足就忽视,满足就赋值,全部弄完,再去假设2号节点是LCA,再去访问一遍。2.3、Tarjan算法流程 并查集 优越的时空复杂度,此算法的时间复杂度可以缩小至O(n+Q),其中,n为数据规模,Q为询问个数。2.4、Tarjan算法的应用举例 此文 中的一个例子。i) 访问1的左子树 STEP 1:从根结点1开始,开始访问结点1、2、3 节点 1 2 3 4 5 6 7 8 祖先 1 2 3
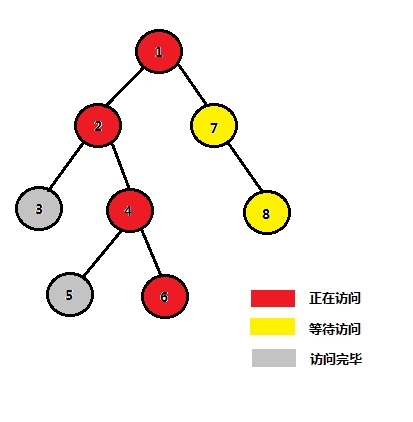
STEP 2:2的左子树结点3访问完毕
节点
1
2
3
4
5
6
7
8
祖先
1
2
2
STEP 3:开始访问2的右子树中的结点4、5、6 节点 1 2 3 4 5 6 7 8 祖先 1 2 2 4 5
STEP 4:4的左子树中的结点5访问完毕 节点 1 2 3 4 5 6 7 8 祖先 1 2 2 4 4
STEP 5:开始访问4的右子树的结点6 节点 1 2 3 4 5 6 7 8 祖先 1 2 2 4 4 6
STEP 6:结点4的左、右子树均访问完毕,故4、5、6中任意两个结点的LCA均为4 节点 1 2 3 4 5 6 7 8 祖先 1 2 2 4 4 4
STEP 7:2的左子树、右子树均访问完毕,故2、3、4、5、6任意两个结点的LCA均为2 节点 1 2 3 4 5 6 7 8 祖先 1 2 2 2 2 2
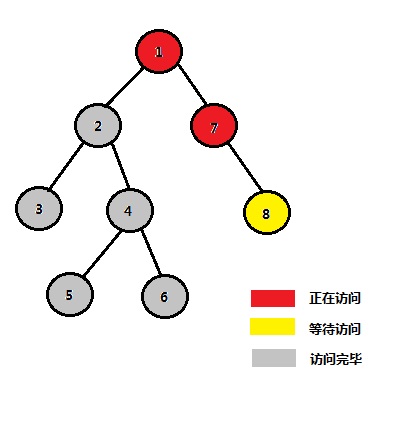
ii) 访问1的右子树 STEP 8:1的左子树访问完毕,开始访问1的右子树 节点 1 2 3 4 5 6 7 8 祖先 1 1 1 1 1 1
STEP 9:开始访问1的右子树中的结点7、8 节点 1 2 3 4 5 6 7 8 祖先 1 1 1 1 1 1 7
STEP 10 节点 1 2 3 4 5 6 7 8 祖先 1 1 1 1 1 1 7 8
STEP 11 节点 1 2 3 4 5 6 7 8 祖先 1 1 1 1 1 1 7 7
STEP 12:1的右子树中的结点7、8访问完毕 节点 1 2 3 4 5 6 7 8 祖先 1 1 1 1 1 1 1 1
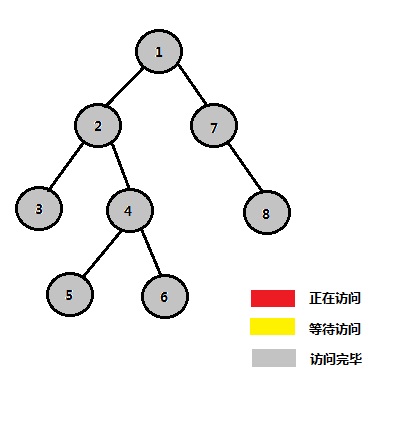
STEP 13:1的左子树、右子树均访问完毕 节点 1 2 3 4 5 6 7 8 祖先 1 1 1 1 1 1 1 1
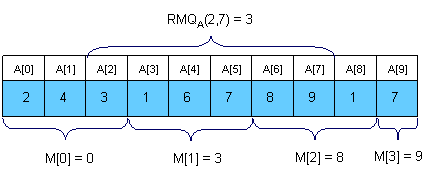
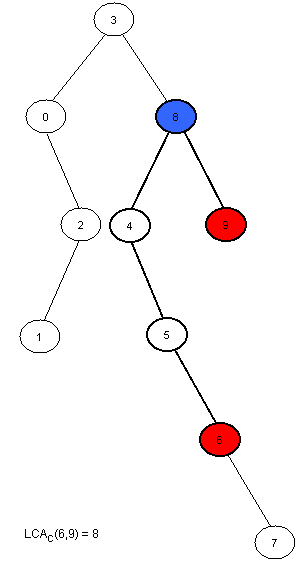
解法三、转换为RMQ问题 “ Range Minimum Query and Lowest Common Ancestor ” ,网上也有翻译版 。在此,我来简单引用 & 总结下。至于为何要总结的原因很简单:因为在这里不总结的话,你不会看晦涩难懂的原文,而在这里总结了,你兴许会看。3.1、什么是RMQ问题 A (i, j) 来表示数组A 中索引i 和 j 之间最小值的位置。 u和v的离树T根结点最远的公共祖先用LCA T(u, v)表示。3.2、如何解决RMQ问题 3.2.1、Trivial algorithms for RMQ //modified by July 2014
void process1(int M[MAXN][MAXN], int A[MAXN], int N)
{
int i, j;
for (i =0; i 复制代码 M[ i ][ j ] 是以i 开始,长度为 2j 的子数组的最小值的索引。这就引出了咱们接下来要介绍的Sparse Table (ST) algorithm。3.2.2、Sparse Table (ST) algorithm 在上图中,我们可以看出:void process2(int M[MAXN][LOGMAXN], int A[MAXN], int N)
{
int i, j;
//initialize M for the intervals with length 1
for (i = 0; i < N; i++)
M[i][0] = i;
//compute values from smaller to bigger intervals
for (j = 1; 1 << j <= N; j++)
for (i = 0; i + (1 << j) - 1 < N; i++)
if (A[M[i][j - 1]] < A[M[i + (1 << (j - 1))][j - 1]])
M[i][j] = M[i][j - 1];
else
M[i][j] = M[i + (1 << (j - 1))][j - 1];
} 复制代码 3.2.3、线段树Segment trees void initialize(int node, int b, int e, int M[MAXIND], int A[MAXN], int N)
{
if (b == e)
M[node] = b;
else
{
//compute the values in the left and right subtrees
initialize(2 * node, b, (b + e) / 2, M, A, N);
initialize(2 * node + 1, (b + e) / 2 + 1, e, M, A, N);
//search for the minimum value in the first and
//second half of the interval
if (A[M[2 * node]] <= A[M[2 * node + 1]])
M[node] = M[2 * node];
else
M[node] = M[2 * node + 1];
}
} 复制代码 int query(int node, int b, int e, int M[MAXIND], int A[MAXN], int i, int j)
{
int p1, p2;
//if the current interval doesn't intersect
//the query interval return -1
if (i > e || j < b)
return -1;
//if the current interval is included in
//the query interval return M[node]
if (b >= i && e <= j)
return M[node];
//compute the minimum position in the
//left and right part of the interval
p1 = query(2 * node, b, (b + e) / 2, M, A, i, j);
p2 = query(2 * node + 1, (b + e) / 2 + 1, e, M, A, i, j);
//return the position where the overall
//minimum is
if (p1 == -1)
return M[node] = p2;
if (p2 == -1)
return M[node] = p1;
if (A[p1] <= A[p2])
return M[node] = p1;
return M[node] = p2;
} 复制代码 3.3、LCA与RMQ的关联性 3.4、从RMQ到LCA O(N), O(1) >。原文 。其余解法 第四十章、螺旋矩阵 http://discuss.leetcode.com/questions/29/spiral-matrix 。class Solution {
public:
vector spiralOrder(vector& matrix) {
vector result;
if (matrix.empty()) return result;
ssize_t beginX = 0, endX = matrix[0].size() - 1;
ssize_t beginY = 0, endY = matrix.size() - 1;
while (true) {
// From left to right
for (ssize_t i = beginX; i endY) break;
// From top down
for (ssize_t i = beginY; i --endX) break;
// From right to left
for (ssize_t i = endX; i >= beginX; --i)
result.push_back(matrix[endY]);
if (beginY > --endY) break;
// From bottom up
for (ssize_t i = endY; i >= beginY; --i)
result.push_back(matrix[beginX]);
if (++beginX > endX) break;
}
return result;
}
}; 复制代码 
 /2
/2 





















 提升卡
提升卡 置顶卡
置顶卡 沉默卡
沉默卡 喧嚣卡
喧嚣卡 变色卡
变色卡 千斤顶
千斤顶 显身卡
显身卡



