日志
- 分享
Kafka如何优化JVM GC
-
2019-7-29 21:49
-
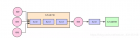
1、Kafka的客户端缓冲机制 首先,先得给大家明确一个事情,那就是在客户端发送消息给kafka服务器的时候,一定是有一个内存缓冲机制的。 也就是说,消息会先写入一个内存缓冲中,然后直到多条消息组成了一个Batch,才会一次网络通信把Batch发送过去。 整个过程如下图所示: 2、内存缓冲造成的频繁GC ...
-
1046 次阅读|0 个评论
- 分享
Flink因为jdk版本造成的错误
-
2019-7-4 09:23
-
caused by java.lang.illegalstateexception:buffer pool is destoryed 我们从网上下载源码,但是不能运行,出现上面错误,是因为jdk的小版本造成的。 比如你使用jdk1.8某个版本,最好尝试另外小版本。 以上内容总结之About云微信群:喜欢讨论技术可以加微信w3aboutyun,拉入技术讨论群 ...
-
1162 次阅读|0 个评论
- 分享
Spark sql写法的重要性
-
2019-6-28 21:47
-
下面写法: select * from where set=0 limit 500 union select * from t b where b.sex=1 limit 5000 产生错误: mismatched input union expection eof 改成: (select * from where set=0 limit 500) union (select * from t b where b.sex=1 limit 5000) 即可解决
-
776 次阅读|0 个评论
- 分享
构建适配Oozie调度的shell任务
-
2019-5-20 11:41
-
Directory Oozie在日常任务调度过程中,可以发起shell action,符合预期的情况是,当oozie调度的脚本执行失败,后续队列的任务也应该失败或者暂停。 但是我们在生产环境发现如果一个负责调度其它任务的shell脚本内部执行任务失败,oozie并不能捕捉到脚本内部任务的状态,猜测是以最后脚本执行的任务状态去判断0或1的 ...
-
884 次阅读|0 个评论
- 分享
k8s常用命令集合
-
2019-5-19 19:50
-
查看集群信息: # kubectl cluster-info 查看更详细的可以用 kubectl cluster-info dump 查看各组件状态 # kubectl -s http://localhost:8080 get componentstatuses GET信息: 输出其它格式和方法(kubectl get -h查看帮助) 查看节点 # kubectl get nodes 查看rc和namespace # kubectl g ...
-
1846 次阅读|0 个评论
- 分享
hbase按行分region,再按列族分store,为什么store内有若干HFile,为啥不存成1个HFile
-
2019-4-25 18:49
-
微信群讨论经典记录: hbase按行分region,再按列族分store,为什么store内有若干HFile,为啥不存成1个HFile hbase的写操作:首先写入到表中region的columnfamily对应的store的memstore。当一个region的所有memstore大于hbase.hregion.memstore.flush.size时,则会把Memstore的数据写出到hdfs中,也就是hfile。 一 ...
-
957 次阅读|0 个评论
- 分享
Cloudera下载100%,重回%0,如此反复的原因是什么
-
2019-4-24 17:01
-
About云微信群中老铁遇到问题,Cloudera下载100%,重回%0,如此反复的原因,原来是因为权限导致。 换成用户:cloudera-scm即可 也就是说可能用户权限导致的
-
693 次阅读|0 个评论
- 分享
hive sql性能优化
-
2019-1-12 19:24
-
hive sql运行慢耗时很长时间该如何优化? 可以把小表放到内存,使用map join;可以把大表拆分为小表,分别取join
-
984 次阅读|0 个评论
- 分享
大数据学习笔记1000条
-
2018-10-29 15:58
-
1. Zookeeper用于集群主备切换。 2. YARN让集群具备更好的扩展性。 3. Spark没有存储能力。 4. Spark的Master负责集群的资源管理,Slave用于执行计算任务。 5. Hadoop从2.x开始,把存储和计算分离开来,形成两个相对独立的子集群:HDFS和YARN,MapReduce依附于YARN来运行。 6. YARN可以为符合YARN编程接口需求的集群 ...
-
897 次阅读|0 个评论
- 分享
spark允许失败的任务,成功的任务跑完
-
2018-9-14 21:03
-
来自:7群:552029443 今天处理数据的时候遇到个问题没搞定想请教下大家,我用spark处理指定目录下的原始文件,文件数量较大,我是整个目录加载,目录下部分原始文件本身有问题,导致spark在处理的时候出现EOFException,Task失败后会重试,但因为部分原始文件本身有问题,重试仍旧会失败,当失败次数达到spark.task.m ...
-
1489 次阅读|0 个评论
- 新手帮助
- 新手帮助:注册遇到问题,领取资源,加入铁粉群,不会使用搜索,如何获取积分等
查看 »

 /2
/2 