日志
hadoop2.2运行mapreduce(wordcount)问题总结
|
本文链接:
http://www.aboutyun.com/thread-7728-1-1.html
问题导读:1.出现Not a valid JAR:可能原因是什么?
2.运行wordcount,路径不正确会报什么错误?
3.一旦输入数据丢失,mapreduce正在运行,会出现什么错误?
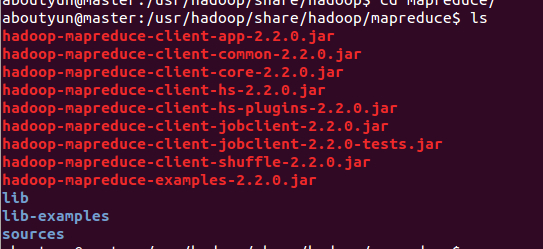
这里对运行mapreduce,做一个问题汇总:第一个问题:Not a valid JAR:
下面举例,对里面的内容分析:
- hadoop jar /hadoop/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.2.0.jar wordcount /data/wordcount /output/wordcount
hadoop-mapreduce-examples-2.2.0.jar 位于下面路径中,所以如果路径不对会报如下错误:
- Not a valid JAR: /hadoop/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.2.0.jar
那么正确写法为:
hadoop jar /usr/hadoop/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.2.0.jar wordcount /data/wordcount /output/wordcount
同时要注意输入输出路径不正确也有可能会报这个错误,还有另外一种就是你的包真的无效了。
第二个问题:Could not complete /tmp/hadoop-yarn/staging/job_1400084979891_0001/job.jar retrying...
这里不断进行尝试,错误表现如下:
- Could not complete /tmp/hadoop-yarn/staging/yonghuming/.staging/job_1400084979891_0001/job.jar retrying...
出上面问题是因为集群处于安全模式,(集群格式化之后,一般会处于安全模式,所以这时候运行mapredcue,最好先检查一下集群模式)
- /hadoop dfsadmin -safemode leave
第三个问题:Could not obtain block: BP-1908912651-172.16.77.15-1399795457132:blk_1073741826_1002
对于上面错误很是不能保存block,但是奇怪的172.16.77.15,并没有挂掉。错误如下:
- hadoop jar /usr/hadoop/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.2.0.jar wordcount /data/wordcount /output/wordcount
- 14/05/14 09:38:55 INFO client.RMProxy: Connecting to ResourceManager at master/172.16.77.15:8032
- 14/05/14 09:38:56 INFO input.FileInputFormat: Total input paths to process : 1
- 14/05/14 09:38:56 INFO mapreduce.JobSubmitter: number of splits:1
- 14/05/14 09:38:56 INFO Configuration.deprecation: user.name is deprecated. Instead, use mapreduce.job.user.name
- 14/05/14 09:38:56 INFO Configuration.deprecation: mapred.jar is deprecated. Instead, use mapreduce.job.jar
- 14/05/14 09:38:56 INFO Configuration.deprecation: mapred.output.value.class is deprecated. Instead, use mapreduce.job.output.value.class
- 14/05/14 09:38:56 INFO Configuration.deprecation: mapreduce.combine.class is deprecated. Instead, use mapreduce.job.combine.class
- 14/05/14 09:38:56 INFO Configuration.deprecation: mapreduce.map.class is deprecated. Instead, use mapreduce.job.map.class
- 14/05/14 09:38:56 INFO Configuration.deprecation: mapred.job.name is deprecated. Instead, use mapreduce.job.name
- 14/05/14 09:38:56 INFO Configuration.deprecation: mapreduce.reduce.class is deprecated. Instead, use mapreduce.job.reduce.class
- 14/05/14 09:38:56 INFO Configuration.deprecation: mapred.input.dir is deprecated. Instead, use mapreduce.input.fileinputformat.inputdir
- 14/05/14 09:38:56 INFO Configuration.deprecation: mapred.output.dir is deprecated. Instead, use mapreduce.output.fileoutputformat.outputdir
- 14/05/14 09:38:56 INFO Configuration.deprecation: mapred.map.tasks is deprecated. Instead, use mapreduce.job.maps
- 14/05/14 09:38:56 INFO Configuration.deprecation: mapred.output.key.class is deprecated. Instead, use mapreduce.job.output.key.class
- 14/05/14 09:38:56 INFO Configuration.deprecation: mapred.working.dir is deprecated. Instead, use mapreduce.job.working.dir
- 14/05/14 09:38:57 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_1400084979891_0002
- 14/05/14 09:38:58 INFO impl.YarnClientImpl: Submitted application application_1400084979891_0002 to ResourceManager at master/172.16.77.15:8032
- 14/05/14 09:38:58 INFO mapreduce.Job: The url to track the job: http://master:8088/proxy/application_1400084979891_0002/
- 14/05/14 09:38:58 INFO mapreduce.Job: Running job: job_1400084979891_0002
- 14/05/14 09:39:19 INFO mapreduce.Job: Job job_1400084979891_0002 running in uber mode : false
- 14/05/14 09:39:19 INFO mapreduce.Job: map 0% reduce 0%
- 14/05/14 09:40:12 INFO mapreduce.Job: map 100% reduce 0%
- 14/05/14 09:40:12 INFO mapreduce.Job: Task Id : attempt_1400084979891_0002_m_000000_0, Status : FAILED
- Error: org.apache.hadoop.hdfs.BlockMissingException: Could not obtain block: BP-1908912651-172.16.77.15-1399795457132:blk_1073741826_1002
- file=/data/wordcount/inputWord
- at org.apache.hadoop.hdfs.DFSInputStream.chooseDataNode(DFSInputStream.java:838)
- at org.apache.hadoop.hdfs.DFSInputStream.blockSeekTo(DFSInputStream.java:526)
- at org.apache.hadoop.hdfs.DFSInputStream.readWithStrategy(DFSInputStream.java:749)
- at org.apache.hadoop.hdfs.DFSInputStream.read(DFSInputStream.java:793)
- at java.io.DataInputStream.read(DataInputStream.java:100)
- at org.apache.hadoop.util.LineReader.readDefaultLine(LineReader.java:211)
- at org.apache.hadoop.util.LineReader.readLine(LineReader.java:174)
- at org.apache.hadoop.mapreduce.lib.input.LineRecordReader.nextKeyValue(LineRecordReader.java:164)
- at org.apache.hadoop.mapred.MapTask$NewTrackingRecordReader.nextKeyValue(MapTask.java:532)
- at org.apache.hadoop.mapreduce.task.MapContextImpl.nextKeyValue(MapContextImpl.java:80)
- at org.apache.hadoop.mapreduce.lib.map.WrappedMapper$Context.nextKeyValue(WrappedMapper.java:91)
- at org.apache.hadoop.mapreduce.Mapper.run(Mapper.java:144)
- at org.apache.hadoop.mapred.MapTask.runNewMapper(MapTask.java:763)
- at org.apache.hadoop.mapred.MapTask.run(MapTask.java:339)
- at org.apache.hadoop.mapred.YarnChild$2.run(YarnChild.java:162)
- at java.security.AccessController.doPrivileged(Native Method)
- at javax.security.auth.Subject.doAs(Subject.java:415)
- at org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:1491)
- at org.apache.hadoop.mapred.YarnChild.main(YarnChild.java:157)
- 14/05/14 09:40:14 INFO mapreduce.Job: map 0% reduce 0%
- 14/05/14 09:41:09 INFO mapreduce.Job: Task Id : attempt_1400084979891_0002_m_000000_1, Status : FAILED
- Error: org.apache.hadoop.hdfs.BlockMissingException: Could not obtain block: BP-1908912651-172.16.77.15-1399795457132:blk_1073741826_1002
- file=/data/wordcount/inputWord
- at org.apache.hadoop.hdfs.DFSInputStream.chooseDataNode(DFSInputStream.java:838)
- at org.apache.hadoop.hdfs.DFSInputStream.blockSeekTo(DFSInputStream.java:526)
- at org.apache.hadoop.hdfs.DFSInputStream.readWithStrategy(DFSInputStream.java:749)
- at org.apache.hadoop.hdfs.DFSInputStream.read(DFSInputStream.java:793)
- at java.io.DataInputStream.read(DataInputStream.java:100)
- at org.apache.hadoop.util.LineReader.readDefaultLine(LineReader.java:211)
- at org.apache.hadoop.util.LineReader.readLine(LineReader.java:174)
- at org.apache.hadoop.mapreduce.lib.input.LineRecordReader.nextKeyValue(LineRecordReader.java:164)
- at org.apache.hadoop.mapred.MapTask$NewTrackingRecordReader.nextKeyValue(MapTask.java:532)
- at org.apache.hadoop.mapreduce.task.MapContextImpl.nextKeyValue(MapContextImpl.java:80)
- at org.apache.hadoop.mapreduce.lib.map.WrappedMapper$Context.nextKeyValue(WrappedMapper.java:91)
- at org.apache.hadoop.mapreduce.Mapper.run(Mapper.java:144)
- at org.apache.hadoop.mapred.MapTask.runNewMapper(MapTask.java:763)
- at org.apache.hadoop.mapred.MapTask.run(MapTask.java:339)
- at org.apache.hadoop.mapred.YarnChild$2.run(YarnChild.java:162)
- at java.security.AccessController.doPrivileged(Native Method)
- at javax.security.auth.Subject.doAs(Subject.java:415)
- at org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:1491)
- at org.apache.hadoop.mapred.YarnChild.main(YarnChild.java:157)
- 14/05/14 09:41:33 INFO mapreduce.Job: Task Id : attempt_1400084979891_0002_m_000000_2, Status : FAILED
- Error: org.apache.hadoop.hdfs.BlockMissingException: Could not obtain block: BP-1908912651-172.16.77.15-1399795457132:blk_1073741826_1002
- file=/data/wordcount/inputWord
- at org.apache.hadoop.hdfs.DFSInputStream.chooseDataNode(DFSInputStream.java:838)
- at org.apache.hadoop.hdfs.DFSInputStream.blockSeekTo(DFSInputStream.java:526)
- at org.apache.hadoop.hdfs.DFSInputStream.readWithStrategy(DFSInputStream.java:749)
- at org.apache.hadoop.hdfs.DFSInputStream.read(DFSInputStream.java:793)
- at java.io.DataInputStream.read(DataInputStream.java:100)
- at org.apache.hadoop.util.LineReader.readDefaultLine(LineReader.java:211)
- at org.apache.hadoop.util.LineReader.readLine(LineReader.java:174)
- at org.apache.hadoop.mapreduce.lib.input.LineRecordReader.nextKeyValue(LineRecordReader.java:164)
- at org.apache.hadoop.mapred.MapTask$NewTrackingRecordReader.nextKeyValue(MapTask.java:532)
- at org.apache.hadoop.mapreduce.task.MapContextImpl.nextKeyValue(MapContextImpl.java:80)
- at org.apache.hadoop.mapreduce.lib.map.WrappedMapper$Context.nextKeyValue(WrappedMapper.java:91)
- at org.apache.hadoop.mapreduce.Mapper.run(Mapper.java:144)
- at org.apache.hadoop.mapred.MapTask.runNewMapper(MapTask.java:763)
- at org.apache.hadoop.mapred.MapTask.run(MapTask.java:339)
- at org.apache.hadoop.mapred.YarnChild$2.run(YarnChild.java:162)
- at java.security.AccessController.doPrivileged(Native Method)
- at javax.security.auth.Subject.doAs(Subject.java:415)
- at org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:1491)
- at org.apache.hadoop.mapred.YarnChild.main(YarnChild.java:157)
- 14/05/14 09:41:59 INFO mapreduce.Job: map 100% reduce 100%
- 14/05/14 09:41:59 INFO mapreduce.Job: Job job_1400084979891_0002 failed with state FAILED due to: Task failed task_1400084979891_0002_m_000000
- Job failed as tasks failed. failedMaps:1 failedReduces:0
- 14/05/14 09:41:59 INFO mapreduce.Job: Counters: 5
- Job Counters
- Failed map tasks=4
- Launched map tasks=4
- Other local map tasks=4
- Total time spent by all maps in occupied slots (ms)=152716
- Total time spent by all reduces in occupied slots (ms)=0
- hadoop fs -text /data/wordcount/inputWord
inputWord是上传文件的内容,如果查看不了,如下错误,说明说明DataNode失去连接,或则已经不能使用了
- hadoop fs -text /data/wordcount/inputWord
- 14/05/14 10:29:23 INFO hdfs.DFSClient: No node available for BP-1908912651-172.16.77.15-1399795457132:blk_1073741826_1002 file=/data/wordcount/inputWord
- 14/05/14 10:29:23 INFO hdfs.DFSClient: Could not obtain BP-1908912651-172.16.77.15-1399795457132:blk_1073741826_1002 from any node: java.io.IOException: No live nodes
- contain current block. Will get new block locations from namenode and retry...
- 14/05/14 10:29:23 WARN hdfs.DFSClient: DFS chooseDataNode: got # 1 IOException, will wait for 1611.781101650108 msec.
- 14/05/14 10:29:24 INFO hdfs.DFSClient: No node available for BP-1908912651-172.16.77.15-1399795457132:blk_1073741826_1002 file=/data/wordcount/inputWord
- 14/05/14 10:29:24 INFO hdfs.DFSClient: Could not obtain BP-1908912651-172.16.77.15-1399795457132:blk_1073741826_1002 from any node: java.io.IOException: No live nodes
- contain current block. Will get new block locations from namenode and retry...
- 14/05/14 10:29:24 WARN hdfs.DFSClient: DFS chooseDataNode: got # 2 IOException, will wait for 3653.3994797694913 msec.
- 14/05/14 10:29:28 INFO hdfs.DFSClient: No node available for BP-1908912651-172.16.77.15-1399795457132:blk_1073741826_1002 file=/data/wordcount/inputWord
- 14/05/14 10:29:28 INFO hdfs.DFSClient: Could not obtain BP-1908912651-172.16.77.15-1399795457132:blk_1073741826_1002 from any node: java.io.IOException: No live nodes
- contain current block. Will get new block locations from namenode and retry...
- 14/05/14 10:29:28 WARN hdfs.DFSClient: DFS chooseDataNode: got # 3 IOException, will wait for 6618.009385385317 msec.
- 14/05/14 10:29:35 WARN hdfs.DFSClient: DFS Read
- org.apache.hadoop.hdfs.BlockMissingException: Could not obtain block: BP-1908912651-172.16.77.15-1399795457132:blk_1073741826_1002 file=/data/wordcount/inputWord
- at org.apache.hadoop.hdfs.DFSInputStream.chooseDataNode(DFSInputStream.java:838)
- at org.apache.hadoop.hdfs.DFSInputStream.blockSeekTo(DFSInputStream.java:526)
- at org.apache.hadoop.hdfs.DFSInputStream.readWithStrategy(DFSInputStream.java:749)
- at org.apache.hadoop.hdfs.DFSInputStream.read(DFSInputStream.java:793)
- at org.apache.hadoop.hdfs.DFSInputStream.read(DFSInputStream.java:601)
- at java.io.DataInputStream.readShort(DataInputStream.java:312)
- at org.apache.hadoop.fs.shell.Display$Text.getInputStream(Display.java:130)
- at org.apache.hadoop.fs.shell.Display$Cat.processPath(Display.java:98)
- at org.apache.hadoop.fs.shell.Command.processPaths(Command.java:306)
- at org.apache.hadoop.fs.shell.Command.processPathArgument(Command.java:278)
- at org.apache.hadoop.fs.shell.Command.processArgument(Command.java:260)
- at org.apache.hadoop.fs.shell.Command.processArguments(Command.java:244)
- at org.apache.hadoop.fs.shell.Command.processRawArguments(Command.java:190)
- at org.apache.hadoop.fs.shell.Command.run(Command.java:154)
- at org.apache.hadoop.fs.FsShell.run(FsShell.java:255)
- at org.apache.hadoop.util.ToolRunner.run(ToolRunner.java:70)
- at org.apache.hadoop.util.ToolRunner.run(ToolRunner.java:84)
- at org.apache.hadoop.fs.FsShell.main(FsShell.java:305)
- text: Could not obtain block: BP-1908912651-172.16.77.15-1399795457132:blk_1073741826_1002 file=/data/wordcount/inputWord





 /2
/2 