日志
如何编译自己想要的spark安装包
问题导读
1.编译失败的可能问题有哪些?
2.指定hadoop版本,需要添加什么配置?
3.如不添加profile,会出现什么问题?

上一篇:
spark编译1:构建基于hadoop的spark安装包
http://www.aboutyun.com/forum.php?mod=viewthread&tid=23257
spark编译时间还是比较长的,可能要一两个小时,而且有时候卡住那不动。
在编译的过程中,有编译失败,也有编译成功的。总之两个条件:
1.跟版本有关系
版本不对,可能编译失败
2.跟网速有关系
网速不好,有些下载失败,导致编译失败。
使用hadoop2.6.5
spark源码下载:
链接:http://pan.baidu.com/s/1gfMpTqb 密码:c6dc
这里使用的是spark2.3.0,hadoop版本为2.6.5,最后编译失败。报错如下
有一个错误和警告是比较关键的
[WARNING] The requested profile "hadoop-2.6.5" could not be activated because it does not exist.
[ERROR] Failed to execute goal net.alchim31.maven:scala-maven-plugin:3.2.2:testCompile (scala-test-compile-first) on project spark-sql_2.11:
上面是profile中是没有hadoop-2.6.5,因此我们需要增加profile
第二个问题不能执行,这个可能就跟网速有关系。多次执行仍然失败,也可能跟版本有关系
更换hadoop2.7.1
上面失败,接着我们尝试hadoop2.7.1
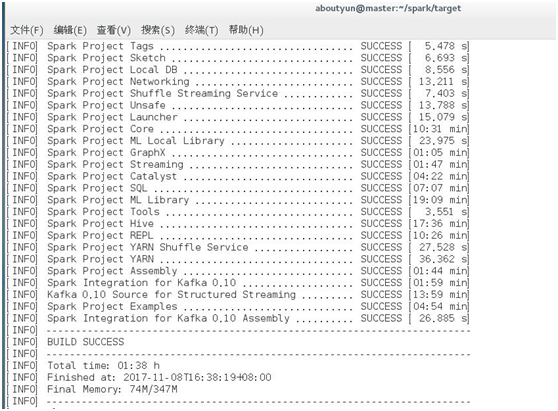
编译成功
但是报错如下
[WARNING] The requested profile "hadoop-2.7.1" could not be activated because it does not exist.这句很关键,意思是虽然编译成功,但是不能使用。在后面将截图给大家看。
所以在pom.xml文件中添加如下属性
编译成功
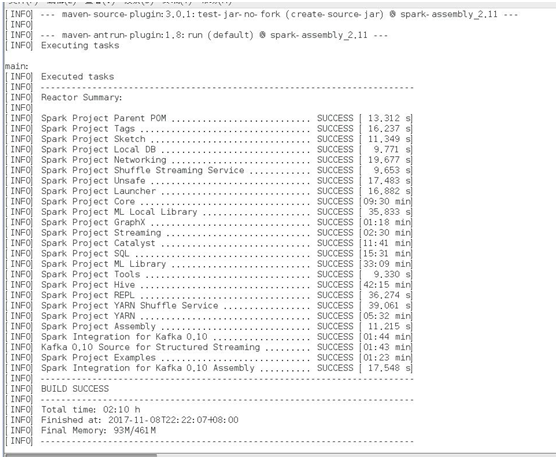
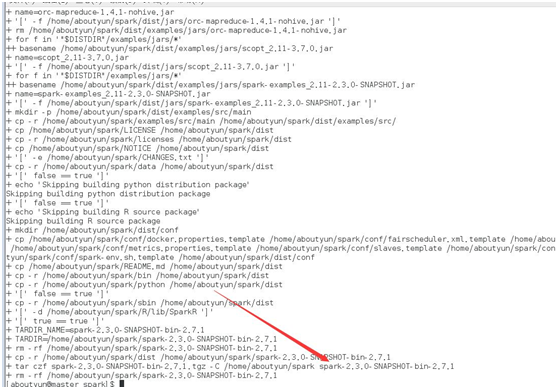
下面我们通过winscp查看第一个为未添加profile,第二个添加后,编译成功。
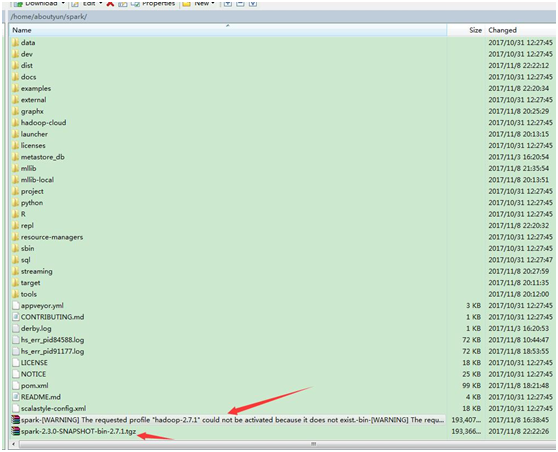

编译包下载:
链接:http://pan.baidu.com/s/1nv7QAwT 密码:oo2r
1.编译失败的可能问题有哪些?
2.指定hadoop版本,需要添加什么配置?
3.如不添加profile,会出现什么问题?
上一篇:
spark编译1:构建基于hadoop的spark安装包
http://www.aboutyun.com/forum.php?mod=viewthread&tid=23257
spark编译时间还是比较长的,可能要一两个小时,而且有时候卡住那不动。
在编译的过程中,有编译失败,也有编译成功的。总之两个条件:
1.跟版本有关系
版本不对,可能编译失败
2.跟网速有关系
网速不好,有些下载失败,导致编译失败。
使用hadoop2.6.5
spark源码下载:
链接:http://pan.baidu.com/s/1gfMpTqb 密码:c6dc
[Bash shell] 纯文本查看 复制代码
1 | $SPARK_SRC/make-distribution.sh --tgz -Pyarn -Phadoop-2.6.5 -Dhadoop.version=2.6.5 -Phive |
这里使用的是spark2.3.0,hadoop版本为2.6.5,最后编译失败。报错如下
[Bash shell] 纯文本查看 复制代码
01 02 03 04 05 06 07 08 09 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 | [INFO] [INFO] ------------------------------------------------------------------------ [INFO] ------------------------------------------------------------------------ [INFO] Reactor Summary: [INFO] [INFO] Skipping Spark Integration for Kafka 0.10 Assembly [INFO] This project has been banned from the build due to previous failures. [INFO] ------------------------------------------------------------------------ [INFO] Spark Project Parent POM ........................... SUCCESS [08:36 min] [INFO] Spark Project Tags ................................. SUCCESS [04:56 min] [INFO] Spark Project Sketch ............................... SUCCESS [ 10.413 s] [INFO] Spark Project Local DB ............................. SUCCESS [01:15 min] [INFO] Spark Project Networking ........................... SUCCESS [ 36.812 s] [INFO] Spark Project Shuffle Streaming Service ............ SUCCESS [ 11.964 s] [INFO] Spark Project Unsafe ............................... SUCCESS [ 34.261 s] [INFO] Spark Project Launcher ............................. SUCCESS [02:40 min] [INFO] Spark Project Core ................................. SUCCESS [12:34 min] [INFO] Spark Project ML Local Library ..................... SUCCESS [02:19 min] [INFO] Spark Project GraphX ............................... SUCCESS [01:29 min] [INFO] Spark Project Streaming ............................ SUCCESS [01:52 min] [INFO] Spark Project Catalyst ............................. SUCCESS [05:25 min] [INFO] Spark Project SQL .................................. FAILURE [10:13 min] [INFO] Spark Project ML Library ........................... SKIPPED [INFO] Spark Project Tools ................................ SUCCESS [ 17.955 s] [INFO] Spark Project Hive ................................. SKIPPED [INFO] Spark Project REPL ................................. SKIPPED [INFO] Spark Project YARN Shuffle Service ................. SUCCESS [ 19.981 s] [INFO] Spark Project YARN ................................. SUCCESS [01:14 min] [INFO] Spark Project Assembly ............................. SKIPPED [INFO] Spark Integration for Kafka 0.10 ................... SUCCESS [01:33 min] [INFO] Kafka 0.10 Source for Structured Streaming ......... SKIPPED [INFO] Spark Project Examples ............................. SKIPPED [INFO] Spark Integration for Kafka 0.10 Assembly .......... SKIPPED [INFO] ------------------------------------------------------------------------ [INFO] BUILD FAILURE [INFO] ------------------------------------------------------------------------ [INFO] Total time: 56:26 min [INFO] Finished at: 2017-11-08T10:44:58+08:00 [INFO] Final Memory: 65M/296M [INFO] ------------------------------------------------------------------------ [WARNING] The requested profile "hadoop-2.6.5" could not be activated because it does not exist. [ERROR] Failed to execute goal net.alchim31.maven:scala-maven-plugin:3.2.2:testCompile (scala-test-compile-first) on project spark-sql_2.11: Execution scala-test-compile-first of goal net.alchim31.maven:scala-maven-plugin:3.2.2:testCompile failed. CompileFailed -> [Help 1] [ERROR] [ERROR] To see the full stack trace of the errors, re-run Maven with the -e switch. [ERROR] Re-run Maven using the -X switch to enable full debug logging. [ERROR] [ERROR] For more information about the errors and possible solutions, please read the following articles: [ERROR] [Help 1] http://cwiki.apache.org/confluence/display/MAVEN/PluginExecutionException [ERROR] [ERROR] After correcting the problems, you can resume the build with the command [ERROR] mvn <goals> -rf :spark-sql_2.11 |
有一个错误和警告是比较关键的
[WARNING] The requested profile "hadoop-2.6.5" could not be activated because it does not exist.
[ERROR] Failed to execute goal net.alchim31.maven:scala-maven-plugin:3.2.2:testCompile (scala-test-compile-first) on project spark-sql_2.11:
上面是profile中是没有hadoop-2.6.5,因此我们需要增加profile
[XML] 纯文本查看 复制代码
1 2 3 | <profile> <id>hadoop-2.6.5</id> </profile> |
第二个问题不能执行,这个可能就跟网速有关系。多次执行仍然失败,也可能跟版本有关系
更换hadoop2.7.1
上面失败,接着我们尝试hadoop2.7.1
[XML] 纯文本查看 复制代码
1 2 3 | <profile> <id>hadoop-2.6.5</id> </profile> |
编译成功
但是报错如下
[Bash shell] 纯文本查看 复制代码
1 2 3 4 5 6 | + TARDIR_NAME='spark-[WARNING] The requested profile "hadoop-2.7.1" could not be activated because it does not exist.-bin-[WARNING] The requested profile "hadoop-2.7.1" could not be activated because it does not exist.' + TARDIR='/home/aboutyun/spark/spark-[WARNING] The requested profile "hadoop-2.7.1" could not be activated because it does not exist.-bin-[WARNING] The requested profile "hadoop-2.7.1" could not be activated because it does not exist.' + rm -rf '/home/aboutyun/spark/spark-[WARNING] The requested profile "hadoop-2.7.1" could not be activated because it does not exist.-bin-[WARNING] The requested profile "hadoop-2.7.1" could not be activated because it does not exist.' + cp -r /home/aboutyun/spark/dist '/home/aboutyun/spark/spark-[WARNING] The requested profile "hadoop-2.7.1" could not be activated because it does not exist.-bin-[WARNING] The requested profile "hadoop-2.7.1" could not be activated because it does not exist.' + tar czf 'spark-[WARNING] The requested profile "hadoop-2.7.1" could not be activated because it does not exist.-bin-[WARNING] The requested profile "hadoop-2.7.1" could not be activated because it does not exist..tgz' -C /home/aboutyun/spark 'spark-[WARNING] The requested profile "hadoop-2.7.1" could not be activated because it does not exist.-bin-[WARNING] The requested profile "hadoop-2.7.1" could not be activated because it does not exist.' + rm -rf '/home/aboutyun/spark/spark-[WARNING] The requested profile "hadoop-2.7.1" could not be activated because it does not exist.-bin-[WARNING] The requested profile "hadoop-2.7.1" could not be activated because it does not exist.' |
[WARNING] The requested profile "hadoop-2.7.1" could not be activated because it does not exist.这句很关键,意思是虽然编译成功,但是不能使用。在后面将截图给大家看。
所以在pom.xml文件中添加如下属性
[XML] 纯文本查看 复制代码
1 2 3 | <profile> <id>hadoop-2.7.1</id> </profile> |
下面我们通过winscp查看第一个为未添加profile,第二个添加后,编译成功。
编译包下载:
链接:http://pan.baidu.com/s/1nv7QAwT 密码:oo2r





 /2
/2 