日志
ORC存储格式介绍
|
orc历史
ORC的全称是(Optimized Row Columnar),ORC文件格式是一种Hadoop生态圈中的列式存储格式,它的产生早在2013年初,最初产生自Apache Hive,用于降低Hadoop数据存储空间和加速Hive查询速度。
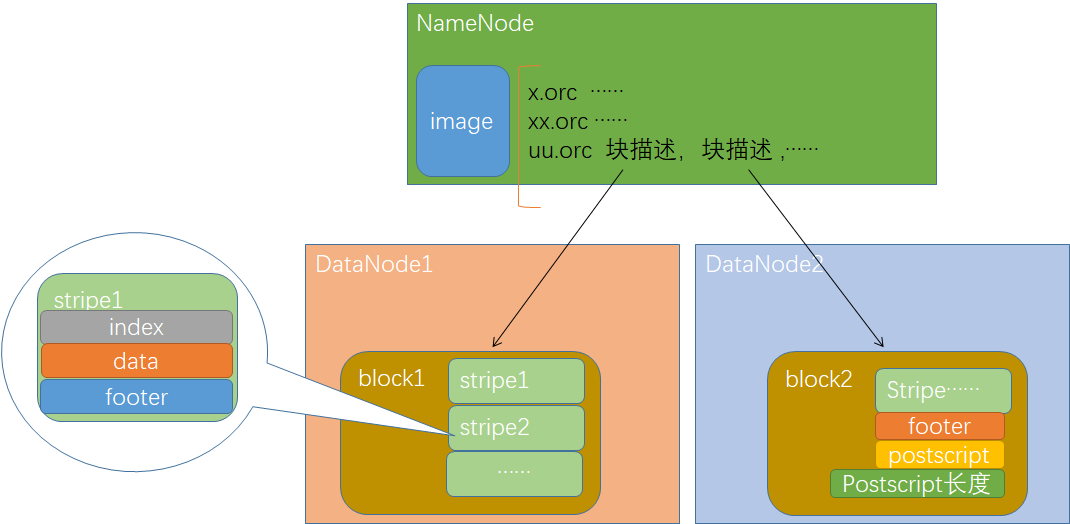
orc结构–----hdfs上的物理视图
orc结构----逻辑视图

orc存储结构解析
orc文件有如下结构快:block,stripe,row_group,stream,index data,Row data,fileFooter,postscript
orc在hdfs上存储,为适应hdfs区块存储思想会将orc文件划分成block块,orc的block块大小一般和hdfs的block块大小一致通过配置( hive.exec.orc.default.block.size 默认256M)指定。每个block块中包含多个stipe,stipe大小通过参数( hive.exec.orc.default.stripe.size 默认64M)指定。应尽量避免strip跨hdfs:block存储,否则在解析stipe时会存在IO跨节点的数据请求,从而增加了系统资源开销。所以,一般orc:block块大小是orc:stripe大小的整数倍。但是,在有些情况下还是会出现block块不能够被整数个stipe完整填满,需要关闭跨hdfs:block的数据存储,需要指定(hive.exec.orc.default.block.padding=false)关闭块存储。另外需要指定最小磁盘利用空间( hive.exec.orc.block.padding.tolerance 默认0.05,例如orc:block=256M,256*0.05=12.5M),hdfs:block块剩余磁盘空间低于此值将放弃使用。
作者:怡仔仔仔
链接:https://www.jianshu.com/p/d322edc18908
来源:简书
简书著作权归作者所有,任何形式的转载都请联系作者获得授权并注明出处。





 /2
/2 