aboutSunFlower 发表于 2016-6-28 20:30 spark job失败是有重试,但是当重试次数达到上线时,如果job还没有执行成功,则任务就会失败! |
freshru 发表于 2016-5-30 17:38 肯定是不会提交job的,必须要有Action,一般会是collect,foreach等来输出数据! |
|
mark 刚开始学习spark 感觉很强大 |
| 认真学习了4遍 |
aboutSunFlower 发表于 2016-6-28 20:30 个人理解spark应该是有保证所有的job都执行成功的机制,比如结合checkpoint什么的 |
| 不过有一点没太搞明白,JobWaiter是在监控job的执行情况,如果jobFailed的话是不是会重新执行一遍?spark会保证所有的job都执行成功吗? |
| 又学到了,楼主分析很详细哦,根据这个,我觉得我的sparkstreaming应该是finalStage,没有进行shuffle |
|
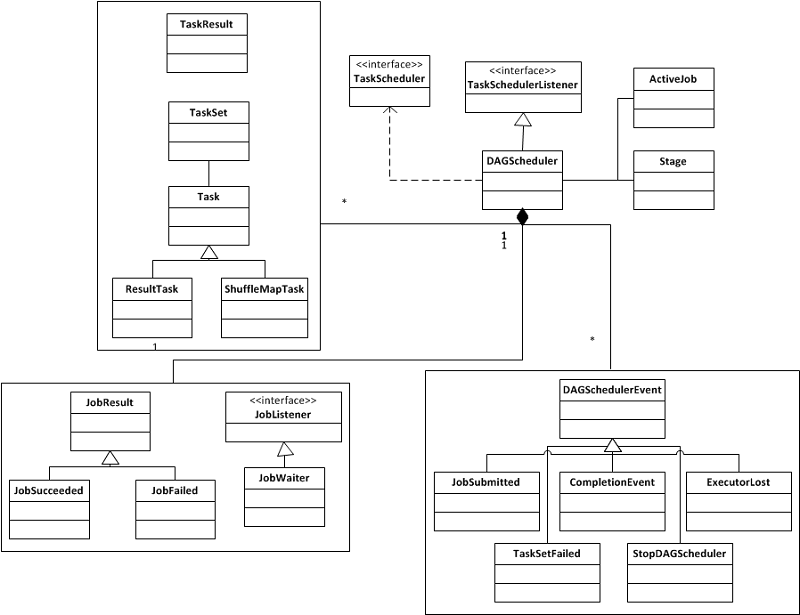
Job的生与死 既然用户提交的job最终会交由 DAGScheduler 去处理,那么我们就来研究一下DAGScheduler 处理job的整个流程。在这里我们分析两种不同类型的job的处理流程。 1.没有shuffle和reduce的job val textFile = sc.textFile("README.md") textFile.filter(line => line.contains("Spark")).count() 复制代码 2.有shuffle和reduce的job val textFile = sc.textFile("README.md") textFile.flatMap(line => line.split(" ")).map(word => (word, 1)).reduceByKey((a, b) => a + b) 复制代码 首先在对 RDD 的 count() 和 reduceByKey() 操作都会调用SparkContext 的 runJob() 来提交job,而 SparkContext 的 runJob() 最终会调用 DAGScheduler 的 runJob() : reduceByKey为transformation操作,textFile.flatMap(line => line.split(" ")).map(word => (word, 1)).reduceByKey((a, b) => a + b)执行完了之后应该还没有生成job,所以会有提交job吗? |
| 楼主,问一下子,本帖中对应的是哪个版本的spark源码呢? |
 /2
/2 
Copyright © 2001-2024 About云-梭伦科技 Powered by Discuz! X3.4 Licensed Discuz Team.
简书 /
![]() 京ICP备2020039040号
京ICP备2020039040号
![]() 简书网举报电话:021-34700000
简书网举报电话:021-34700000