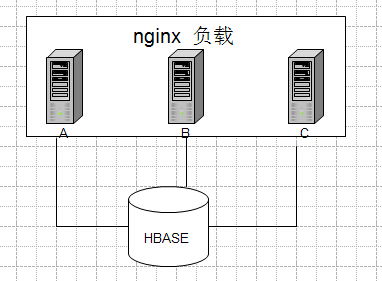
langke93 发表于 2015-4-17 12:47 现在采用的是提交一次直接flush一次,强制刷新到服务器端。否则的话,需要延迟1分钟,htable采用连接池连接。 按你这样的说法,目前似乎也没有好的解决办法了,因为负载的时候不清楚会到哪台机器。 |
尘世随缘 发表于 2015-4-17 12:07 第一个方法 实时和离线其实都是相对的。 可以通过时间和数据量来达到相对实时。 比如达到某个时间,虽然数量不大,但是也flush。 比如达到某个数据量,但是没有达到某个时间,也flush。 也就是只要达到其中一个 条件就flush。 第二个方法 还有一个方法就是: 首先查询各个客户端的缓存,如果都没有那么就到hbase中查询。 |
| 我在补充下,提交一条消息,这时候的消息还是缓存在客户端的,并没有到hbase,所以在另外的一台服务器上执行get肯定是查询不到的。 |
| 这个生产环境已经出现这样的情况了,刚刚插入就开始读,如果web端不负载的话,完全没有问题,如果有负载的话,数据会又延迟。因为另外的机器上的数据没有flush到db中。 |
|
对楼主的说法有些不同的看法: Client端想要插入,删除,查询数据都需要先找到相应的RegionServer。什么叫相应的RegionServer?就是管理你要操作的那个Region的RegionServer。 写入流程: Client写入 -> 存入MemStore,一直到MemStore满 -> Flush成一个StoreFile,直至增长到一定阈值 -> 出发Compact合并操作 -> 多个StoreFile合并成一个StoreFile,同时进行版本合并和数据删除 -> 当StoreFiles Compact后,逐步形成越来越大的StoreFile -> 单个StoreFile大小超过一定阈值后,触发Split操作,把当前Region Split成2个Region,Region会下线,新Split出的2个孩子Region会被HMaster分配到相应的HRegionServer 上。 读取流程: client->zookeeper->.ROOT->.META-> 用户数据表zookeeper记录了.ROOT的路径信息(root只有一个region),.ROOT里记录了.META的region信息, (.META可能有多个region),.META里面记录了region的信息。 从上面得出,hbase读取并不是某个RegionServer上去读取,而是先从.root找到相关信息,然后去读取。所以这和那一台没有太大的关系。 |
 /2
/2 
Copyright © 2001-2024 About云-梭伦科技 Powered by Discuz! X3.4 Licensed Discuz Team.
简书 /
![]() 京ICP备2020039040号
京ICP备2020039040号
![]() 简书网举报电话:021-34700000
简书网举报电话:021-34700000