langke93 发表于 2015-9-2 21:11 我是maven打包的jar,直接运行的。 |
阿斯兰的 发表于 2015-9-2 18:57 是不是引用第三方包了,如果引用了,要在集群上都放上 |
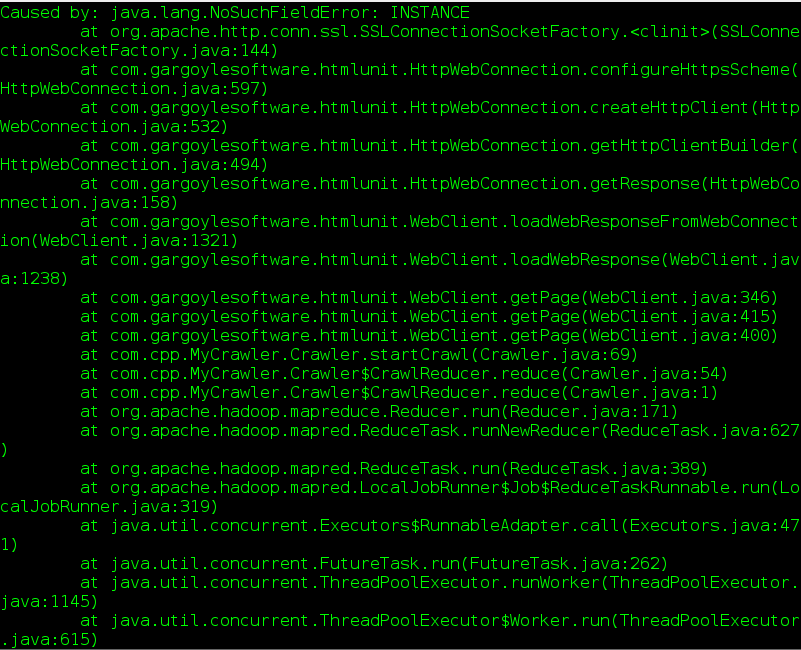
jixianqiuxue 发表于 2015-9-2 18:04 我打印过了,直接用链接执行都不行,HTMLunit代码放在reduce就不行 |
| 人呢,快来人快来人快来人快来人快来人快来人快来人快来人快来人 |
jixianqiuxue 发表于 2015-9-2 18:04 我有打印key.toString()看过是对的啊,而且我直接用链接测试page = webClient.getPage(“http://www.dianping.com”);这样也不行啊。reduce方法有没有什么限制? |
|
程序可能没有错的,而是被处理的文件字段与提取的字段没有对应上 |
| 顶顶顶顶顶顶顶顶顶顶顶顶顶顶顶顶顶顶顶顶顶顶顶顶顶顶顶顶顶顶顶顶顶顶顶顶顶顶顶顶顶顶顶顶顶顶顶顶顶顶顶顶顶顶顶顶顶顶顶顶顶顶顶顶顶顶顶顶顶顶顶顶顶顶顶顶顶顶顶顶顶顶顶顶顶顶顶顶顶顶顶 |
 /2
/2 
Copyright © 2001-2024 About云-梭伦科技 Powered by Discuz! X3.4 Licensed Discuz Team.
简书 /
![]() 京ICP备2020039040号
京ICP备2020039040号
![]() 简书网举报电话:021-34700000
简书网举报电话:021-34700000