| sdsdfsd |
bravecharge 发表于 2016-7-25 14:10 是这样的,按照《Hive编程指南》的说法: 第一点: 如果分区过多-->创建大量的hadoop文件和文件夹-->Namenode需要维护大量的信息(存储在内存中)-->Hdfs就会爆掉。 第二点: 每个MR任务会转换成Task-->每个Task是新的JVM实例(开启、销毁开销很大)-->每个文件都对应一个task。 这就导致JVM开启和销毁的时间会很长...甚至超过计算的时间。 理想的方案:不要太多的分区和文件目录,每个文件目录的文件最好很大。 参考《Hive编程指南》127页 |
| 有个疑惑是 hive 是否有对分区目录数做限制, 假如我的分区目录数太多的话 会不会有什么隐患? |
|
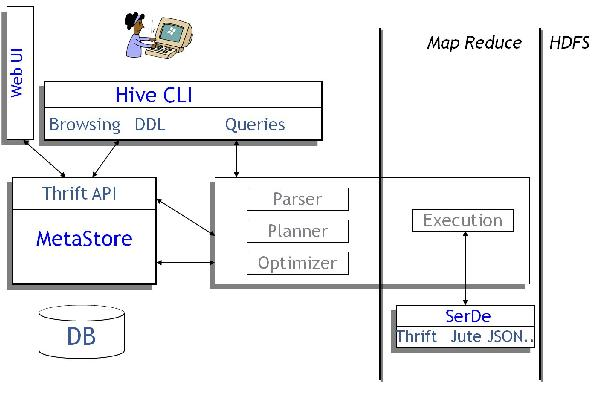
对hive和RDBMS有一个较为感性的认识了! 适合初次接入者 |
 /2
/2 
Copyright © 2001-2024 About云-梭伦科技 Powered by Discuz! X3.4 Licensed Discuz Team.
简书 /
![]() 京ICP备2020039040号
京ICP备2020039040号
![]() 简书网举报电话:021-34700000
简书网举报电话:021-34700000