nextuser 发表于 2016-8-10 15:36 试过了,加上@transient还是会出现这个异常,原因就在于在map中调用了sparkcontext方法,我已经用groupbykey和map代替了reducebykey算子。。。 |
nike1972 发表于 2016-8-10 13:46 代码尝试加上 @transient @transient val conf = new SparkConf(); @transient val sc = new SparkContext(conf); |
nike1972 发表于 2016-8-10 09:16 具体是什么异常,贴出来看下 |
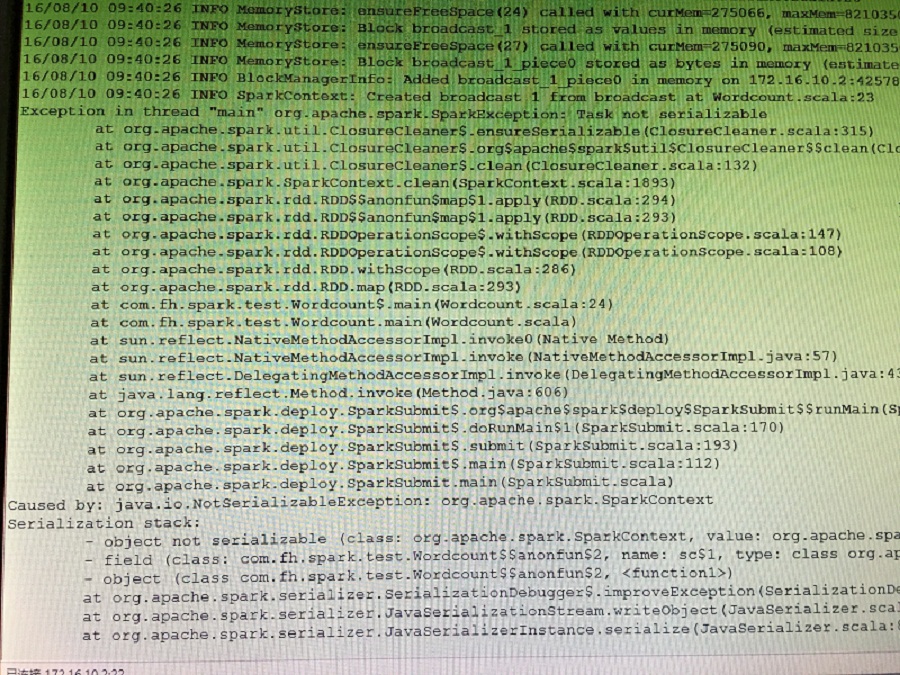
einhep 发表于 2016-8-10 06:12 我也想到了使用广播变量,但是我现在要对map中得到的值进行传递,在map中使用sc的时候总会造成task 没有序列化这个异常,这个问题如何解决呢? |
nike1972 发表于 2016-8-9 22:50 context应该是hadoop的, Spark 支持 2 种类型的共享变量:广播变量(broadcast variables),用来在所有节点的内存中缓存一个值;累加器(accumulators),仅仅只能执行“添加(added)”操作,例如:记数器(counters)和求和(sums)。 楼主可以尝试上面的。 网上资料也不少 推荐参考 Spark中文手册1-编程指南 http://www.aboutyun.com/forum.php?mod=viewthread&tid=11413 |
langke93 发表于 2016-8-9 22:37 能不能说的具体一点?刚接触spark,很多不是太懂,我需要有一个字符串的数据能够在map中进行赋值,然后在reduce中对赋值的结果进行操作。用context如何进行? |
|
这是分布式编程跟传统编程不一样的。 全局变量也是不管用的。 因为map函数和reduce函数可能会在不同的机器上执行。 可以尝试使用context |
 /2
/2 
Copyright © 2001-2024 About云-梭伦科技 Powered by Discuz! X3.4 Licensed Discuz Team.
简书 /
![]() 京ICP备2020039040号
京ICP备2020039040号
![]() 简书网举报电话:021-34700000
简书网举报电话:021-34700000