|
消费者的活跃度 作为消费组的一部分,每个消费者会被分配它订阅的topics的一部分partitions.就像在这些partitions上加了一个组锁. 只要锁被持有,组中的其他成员就不会读取他们(译注:每个partition都对应唯一的消费者,partition锁只属于唯一的消费者). 当你的消费者是正常状态时,当然是最好不过了,因为这是防止重复消费的唯一方式. 但如果消费者失败了,你需要释放掉那个锁,这样可以将partitions分配给其他健康的成员. kafka的消费组协调协议使用心跳机制解决了这个问题.在每次rebalance,所有当前generation的成员都会定时地发送心跳给group协调者. 只要协调者持续接收到心跳,它会假设这个成员是健康的. 每次接收到心跳,协调者就开始或者重置计时器. 如果时间超过了,没有收到消费者的心跳,协调者标记消费者为死亡状态,并触发组中其他的消费者重新加入,来重新分配partitions. 计时器的时间间隔就是session timeout,即客户端应用程序中配置的session.timeout.ms session timeout确保应用程序崩溃或者partition将消费者和协调者进行了隔离的情况下锁会被释放. 注意应用程序的失败(进程还存在)有点不同,因为消费者仍然会发送心跳给协调者,并不代表应用程序是健康的. 消费者的轮询循环被设计为解决这个问题. 所有的网络IO操作在调用poll或者其他的阻塞API,都是在前台完成的. 消费者并不使用任何的后台线程. 这就意味着消费者的心跳只有在调用poll的时候才会发送给协调者. 如果应用程序停止polling(不管是处理代码抛出异常或者下游系统崩溃了),就不会再发送心跳了, 最终就会导致session超时(没有收到心跳,计时器开始增加), 然后消费组就会开始平衡操作. 唯一存在的问题是如果消费者处理消息花费的时间比session timeout还要长,就会触发一个假的rebalance. 可以通过设置更长的session timeout防止发生这样的情况.默认的超时时间是30秒,设置为几分钟也不是不行的. 更长的session timeout的缺点是,协调者会花费较长时间才能检测到真正崩溃的消费者. 明白了! |
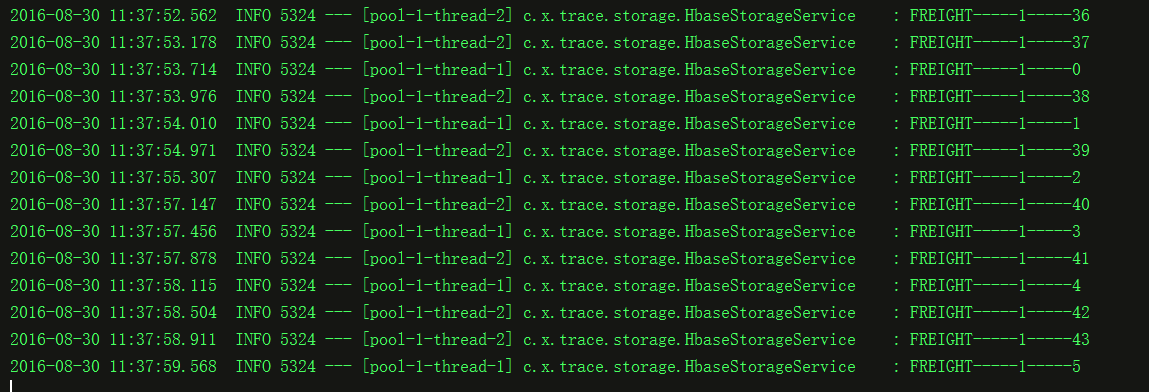
desehawk 发表于 2016-8-30 15:58 刚开始是没有错的。 忘了说明,后面的 log信息是代表 TOPIC-PARTITION-OFFSET 后面可以看到,另外一个线程来拿数据了,这样会拿到重复数据。 我要的理想情况应该是这个线程 什么都不做就好了。如果单线程肯定是没有问题的。 |
|
2016-08-30 11:37:02.951 INFO 5324 --- [pool-1-thread-1] o.a.k.c.c.internals.ConsumerCoordinator : Setting newly assigned partitions [FREIGHT-0] for group FREIGHT 2016-08-30 11:37:02.972 INFO 5324 --- [pool-1-thread-2] o.a.k.c.c.internals.AbstractCoordinator : Successfully joined group FREIGHT with generation 2 2016-08-30 11:37:02.973 INFO 5324 --- [pool-1-thread-2] o.a.k.c.c.internals.ConsumerCoordinator : Setting newly assigned partitions [FREIGHT-1] for group FREIGHT 可以看下红字部分,应该是按照楼主的思路来的。 两个同组的消费者对应两个不同的分区。刚开始 partitions [FREIGHT-1] 有数据,对应- [pool-1-thread-2] 开始消费数据 partitions [FREIGHT-0] 有数据后, [pool-1-thread-1]开始消费 |
 /2
/2 
Copyright © 2001-2024 About云-梭伦科技 Powered by Discuz! X3.4 Licensed Discuz Team.
简书 /
![]() 京ICP备2020039040号
京ICP备2020039040号
![]() 简书网举报电话:021-34700000
简书网举报电话:021-34700000