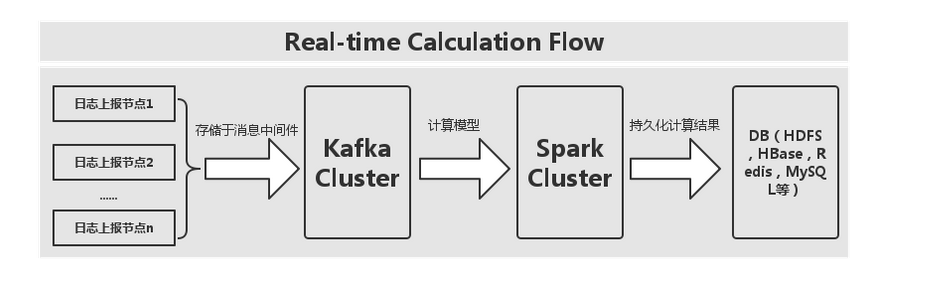
|
scala需要补充一下 |
yht 发表于 2017-10-8 13:13 将rdd保存成 parquet格式,可以指定 mode为 append,可以将多个batch数据写入到一个文件 |
| 感谢分享 |
einhep 发表于 2017-10-7 18:14 嗯嗯 早上群里看到了 十分感谢等下就拜读下 |
yht 发表于 2017-10-6 09:59 这篇文章有介绍的,楼主可以尝试下。 用Hadoop的FileSystem实现在已有目录下用一个文件保存Spark数据 http://www.aboutyun.com/forum.php?mod=viewthread&tid=22855 |
desehawk 发表于 2017-10-6 08:23 这种方式多个partition会聚合成一个输出,但是对于多个batch每次都saveasfile 貌似不行。。每个batch都会保存为一个文件 |
yht 发表于 2017-10-5 12:44 关键是在实现过程中需要注意的一些问题,比如对象的序列化问题 这个代码体现哪里呢。。。。spark的RDD运算确实比storm逻辑实现能力强大很多。不过两者实时性还是感觉有区别,一个batch 一个一条一条处理。前两天也在做类似的操作,用sparkStream 入平台HDFS但是发现出现大量细碎文件(我每个batch设置5秒),请问spark stream下有米方便的方法让batch追加到同一个文件。还是自己要去写文件操作? [mw_shl_code=scala,true]rddx.repartition(1).saveAsTextFile("test/test.txt") rddx.coalesce(1).saveAsTextFile("test/test.txt")[/mw_shl_code] |
| 感谢分享 |
| 关键是在实现过程中需要注意的一些问题,比如对象的序列化问题 这个代码体现哪里呢。。。。spark的RDD运算确实比storm逻辑实现能力强大很多。不过两者实时性还是感觉有区别,一个batch 一个一条一条处理。前两天也在做类似的操作,用sparkStream 入平台HDFS但是发现出现大量细碎文件(我每个batch设置5秒),请问spark stream下有米方便的方法让batch追加到同一个文件。还是自己要去写文件操作? |
 /2
/2 
Copyright © 2001-2024 About云-梭伦科技 Powered by Discuz! X3.4 Licensed Discuz Team.
简书 /
![]() 京ICP备2020039040号
京ICP备2020039040号
![]() 简书网举报电话:021-34700000
简书网举报电话:021-34700000