|
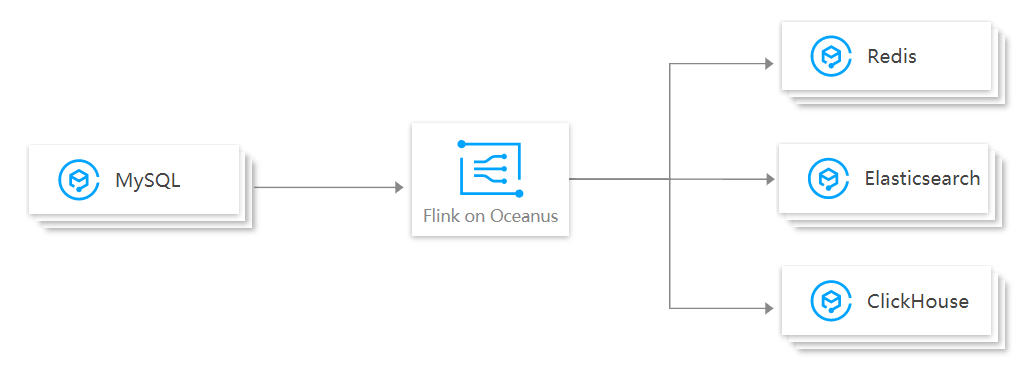
Flink CDC • ЪЧБфИќЪ§ОнЛёШЁЕФЫѕаД ЃЈChange Data CaptureЃЉ • НЋдДЪ§Он ЃЈSourceЃЉЕФБфЖЏЭЌВНЕНвЛИіЛђепЖрИіФПЕФЕи (Sink) • дйЭЌВНЕФЙ§ГЬжаПЩвдЖдЪ§ОнНјаавЛаЉЖюЭтВйзї ЃЈGROUP BY | JOIN | ...ЃЉ • НтОі: ЖдЭЌвЛЗнЪ§ОнЖрДЮЯТГСЕФГЁОАЃЌНтОіДЋЭГЗНЪНЖдвЛЗнЪ§ОнЖрДЮЗжЗЂЕФВйзї • БШШчТфЕиЃК Redis | Elasticsearch | ClickHouse ЪЕЯжФЃЪН жїЖЏВщбЏ • дкЪ§ОндДБэжа БЃДцЩЯДЮИќаТЕФЪБМфДСИњАцБОКХ • ЯТгЮЭЈЙ§ВЛЖЯВщбЏКЭЩЯДЮМЧТМзіЖдБШЃЌРДШЗЖЈЪ§ОнЪЧЗёгаБфЖЏЃЌЪЧЗёашвЊЭЌВН • гХЕуЃКВЛЩцМАЕзВу binlog ЕФВЩМЏгыНтЮі ЃЈМѕЩйЪ§ОнДЋЪфЙ§ГЬЃЉ • ШБЕуЃКЯТгЮашвЊВЛЖЯВщбЏЖдЪ§ОнПт Service габЙСІ ЪТМўНгЪе • ЭЈЙ§ДЅЗЂЦї Trigger Лђеп ШежОЕФВйзїМЧТМИУЪТМў ЃЈР§Шч Transaction logЁЂBinary logЁЂWrite-ahead logЃЉ • дДЪ§ОнЗЂЩњИФБфКѓИНМгдк Trigger Лђеп LOG(Binlog) жа • ЯТгЮЭЈЙ§Ъ§ОнПтЕзВуЕФавщЖЉдФВЂЯћЗбетаЉЪТМўЃЌЖдЪ§ОнПтЕФБфЖЏзіЛиЗХЕФаЇЙћ ДяЕНЪ§ОнЕФЭЌВНЙЄзї • гХЕуЃКПЩвдМѕЩйЖдЪ§ОнПт Service ЕФбЙСІЃЌЪЕЪБадБШНЯИп • ШБЕуЃКеыЖдгк LOG ашвЊгаЖдгІЕФНтЮіЙЄОпВЮгыНтЮі ЃЈCanalЁЂDataxЁЂDebeziumЃЉ,бЇЯАГЩБОИп ЪЙгУЗНЗЈ ЪфШы Debezium ЕШЪ§ОнСїНјааЭЌВН • ЬиЕуЃКзіЕНДІРэЕФНтёюЙЄзї | ЖдгкЪ§ОнЕФДІРэЕУЕНЕФНтёюКЯ ЯрЕБгкЪЧ DBServer -> Debezium -> Kafka -> Flink -> TransSink • ШБЕуЃКИіШЫИаОѕЮЌЛЄСПДѓЁЂбЇЯАГЩБОИп жБНгЖдНгЩЯгЮЪ§ОнПтНјааЪ§ОнЭЌВН • ЬиЕуЃКбЇЯАГЩБОаЁЁЂЮоашПМТЧФкВПЯИНкЃЈФкВПЖМзіСЫЗтзАЁЂПЊЯфМДгУЃЉ ЯрЕБгкЪЧ DBServer -> Flink CDC ->TransSink • ШБЕуЃКВЛЭИУїЛЏЁЂФкОлЁЂЪ§ОнАВШЋашвЊПМТЧ ЃЈРрЫЦзівЛаЉМгУмВйзїЃЉ |
 /2
/2 
Copyright © 2001-2024 AboutдЦ-ЫѓТзПЦММ Powered by Discuz! X3.4 Licensed Discuz Team.
МђЪщ /
![]() ОЉICPБИ2020039040КХ
ОЉICPБИ2020039040КХ
![]() МђЪщЭјОйБЈЕчЛАЃК021-34700000
МђЪщЭјОйБЈЕчЛАЃК021-34700000