|
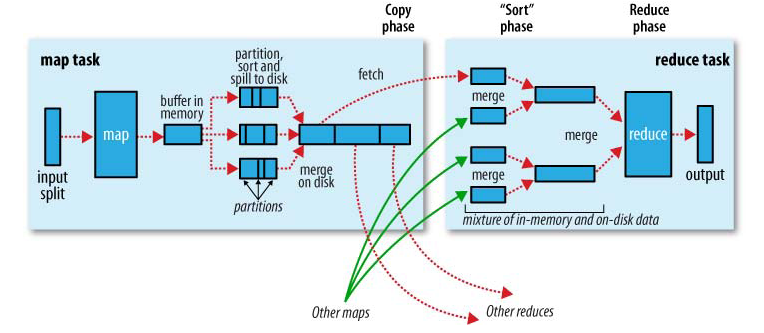
MapReduce不适用那些数据? MapReduce是Hadoop中处理大数据的方法,是一个处理大数据的简单算法、编程泛型。虽然思想简单,但其实真正用起来还是有很多问题,不是所有的问题都可以像WordCount那样典型和直观, 有很多需要trick的地方。MapReduce的中心思想是分而治之,数据要松耦合,可以划分为小数据集并行处理,如果数据本身在计算上存在很强的依赖关系,就不要赶鸭子上架,用MapReduce了。 MapReduce如何降低实现的复杂度? MapReduce编程中,最重要的是要抓住Map和Reduce的input和output,好的input和output可以降低实现的复杂度。 Map端和Reduce端是否都有Shuffle过程? 二者都包含Shuffle |
 /2
/2 
Copyright © 2001-2024 About云-梭伦科技 Powered by Discuz! X3.4 Licensed Discuz Team.
简书 /
![]() 京ICP备2020039040号
京ICP备2020039040号
![]() 简书网举报电话:021-34700000
简书网举报电话:021-34700000