|
这样应该会有点麻烦,你可以用BitMap试试。 将reduce中已经连接的好的分组按照来源标志分别放到两个BitMap中。这样比较省内存。 |
|
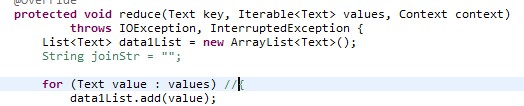
如果在reduce中做连接,该怎么做? |
|
数据量不大直接mapJoin 你其中一个文件很小看到 小的放到一个hashMap里面通过distribute分发,然后比较就ok |
|
写这种程序尽量使内存能够动态流动,而不是常驻型 例如,你为何要复制一份?可不可以不同过复制一份来进行实现。 |
|
检查对象引用是否正确。 另外你这个用的地方不对,很容易造成OOM 只要有某个分组过大你这个就必定OOM了 |
 /2
/2 
Copyright © 2001-2024 About云-梭伦科技 Powered by Discuz! X3.4 Licensed Discuz Team.
简书 /
![]() 京ICP备2020039040号
京ICP备2020039040号
![]() 简书网举报电话:021-34700000
简书网举报电话:021-34700000