|
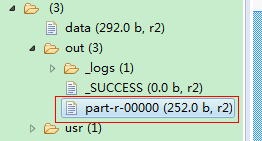
在一般情况下,Hadoop 每一个 Reducer 产生一个输出文件,文件以part-r-00000、part-r-00001 的方式进行命名。 如果需要人为的控制输出文件的命名或者每一个 Reducer 需要写出多个输出文件时,可以采用 MultipleOutputs 类来完成。 MultipleOutputs 采用输出记录的键值对(output Key 和 output Value)或者任意字符串来生成输出文件的名字,文件一般以 name-r-nnnnn 的格式进行命名,其中 name 是程序设置的任意名字;nnnnn 表示分区号。MultipleOutputs 的使用方式 的使用方式: :: :  也就是说你设置的reduce为19在集群上生效了但是在eclipse中没有生效,eclipse在运行的时候默认还是一个reduce。可以尝试下面,通过multipleOutputs来实现看看,是否可以控制多个输出 想要使用 MultipeOutputs,需要完成以下四个步骤: 1. 在 Reducer 中声明 MultipleOutputs 的变量 private MultipleOutputs<NullWritable, Text> multipleOutputs; 2. 在 Reducer 的 setup 函数中进行 MultipleOutputs 的初始化 protected void setup(Context context)throws IOException, InterruptedException { multipleOutputs = new MultipleOutputs<NullWritable, Text>(context); } 3. 在 reduce 函数中进行输出控制 protected void reduce(Text key, Iterable<Text> values, Context context)throws IOException, InterruptedException { for (Text value : values) { multipleOutputs.write(NullWritable.get(), value, key.toString()); } } 4. 在 cleanup 函数中关闭输出 MultipleOutputs protected void cleanup(Context context)throws IOException, InterruptedException { multipleOutputs.close(); } 注意:multipleOutputs.write(key, value, baseOutputPath)方法的第三个函数表明了该输出所在的目录(相对于用户指定的输出目录)。如果baseOutputPath不包含文件分隔符“/”,那么输出的文件格式为baseOutputPath-r-nnnnn(name-r-nnnnn);如果包含文件分隔符“/”,例如baseOutputPath=“029070-99999/1901/part”,那么输出文件则为 |
| eclipse 有自己的JVM空间,不同于HADOOP的JVM,所有在eclipse执行的JOB都不是分布式 |
|
你的开发环境是怎么搭建的那?参考 hadoop开发方式总结及操作指导 插件开发 如果采用的是插件方式,本地环境就是下面目录  当然不要忘记配置环境变量, path,这里使用的是绝对路径,path里面配置的是hadoop的bin路径。配置完毕,切忌重启机器 如下图所示 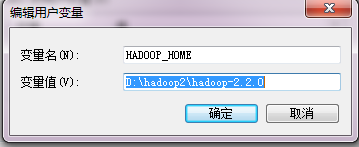 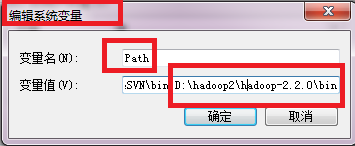 2.添加外部包 如下,被添加的hadoop文件夹就是你的本地环境。 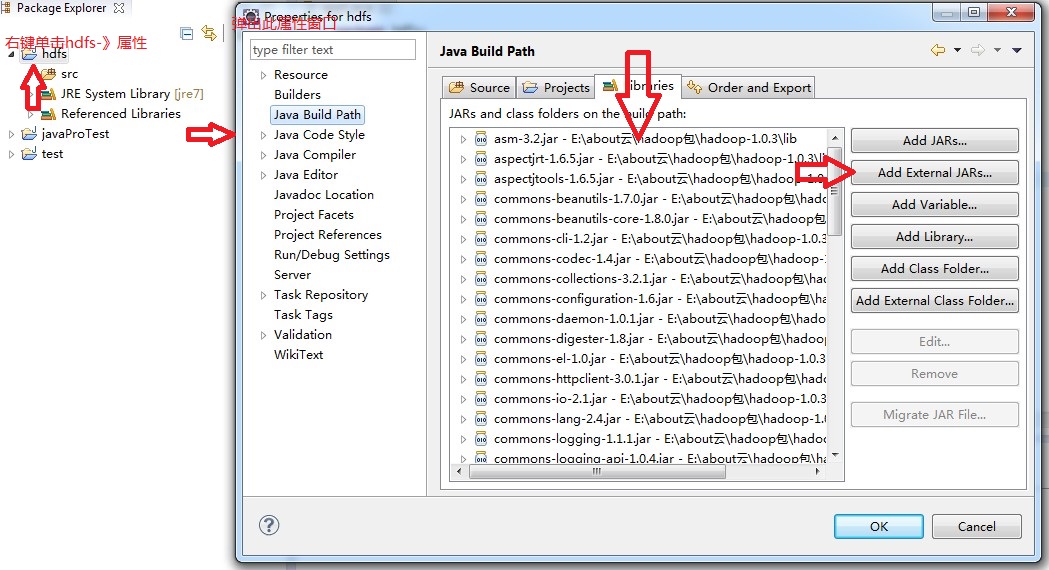 |
desehawk 发表于 2014-10-23 11:34 恩,谢谢,配置文件我知道,所说的“本地”指的是哪里呢? eclipse安装目录下的某个地方还是什么呢? |
|
记得在运行的时候,本地环境(hadoop版本)一定与集群hadoop版本一致 |
Riordon 发表于 2014-10-23 11:27 版主说的配置文件是指: 你的hdfs-site.xml,core-site.xml等在conf下面的配置文件 |
howtodown 发表于 2014-10-23 11:20 “把集群配置文件复制到本地”是什么意思呢?不太明白... |
desehawk 发表于 2014-10-23 11:13 eclipse中控制台信息如下: 14/10/23 11:23:19 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable 14/10/23 11:23:19 WARN mapred.JobClient: Use GenericOptionsParser for parsing the arguments. Applications should implement Tool for the same. 14/10/23 11:23:19 WARN mapred.JobClient: No job jar file set. User classes may not be found. See JobConf(Class) or JobConf#setJar(String). 14/10/23 11:23:19 INFO input.FileInputFormat: Total input paths to process : 1 14/10/23 11:23:19 WARN snappy.LoadSnappy: Snappy native library not loaded 14/10/23 11:23:19 INFO mapred.JobClient: Running job: job_local1543091770_0001 14/10/23 11:23:19 INFO mapred.LocalJobRunner: Waiting for map tasks 14/10/23 11:23:19 INFO mapred.LocalJobRunner: Starting task: attempt_local1543091770_0001_m_000000_0 14/10/23 11:23:19 INFO mapred.Task: Using ResourceCalculatorPlugin : null 14/10/23 11:23:19 INFO mapred.MapTask: Processing split: hdfs://192.168.137.100:9000/data:0+292 14/10/23 11:23:19 INFO mapred.MapTask: io.sort.mb = 100 14/10/23 11:23:19 INFO mapred.MapTask: data buffer = 79691776/99614720 14/10/23 11:23:19 INFO mapred.MapTask: record buffer = 262144/327680 14/10/23 11:23:19 INFO mapred.MapTask: Starting flush of map output 14/10/23 11:23:19 INFO mapred.MapTask: Finished spill 0 14/10/23 11:23:19 INFO mapred.Task: Task:attempt_local1543091770_0001_m_000000_0 is done. And is in the process of commiting 14/10/23 11:23:19 INFO mapred.LocalJobRunner: 14/10/23 11:23:19 INFO mapred.Task: Task 'attempt_local1543091770_0001_m_000000_0' done. 14/10/23 11:23:19 INFO mapred.LocalJobRunner: Finishing task: attempt_local1543091770_0001_m_000000_0 14/10/23 11:23:19 INFO mapred.LocalJobRunner: Map task executor complete. 14/10/23 11:23:19 INFO mapred.Task: Using ResourceCalculatorPlugin : null 14/10/23 11:23:19 INFO mapred.LocalJobRunner: 14/10/23 11:23:19 INFO mapred.Merger: Merging 1 sorted segments 14/10/23 11:23:19 INFO mapred.Merger: Down to the last merge-pass, with 1 segments left of total size: 1094 bytes 14/10/23 11:23:19 INFO mapred.LocalJobRunner: 14/10/23 11:23:19 INFO mapred.Task: Task:attempt_local1543091770_0001_r_000000_0 is done. And is in the process of commiting 14/10/23 11:23:19 INFO mapred.LocalJobRunner: 14/10/23 11:23:19 INFO mapred.Task: Task attempt_local1543091770_0001_r_000000_0 is allowed to commit now 14/10/23 11:23:20 INFO output.FileOutputCommitter: Saved output of task 'attempt_local1543091770_0001_r_000000_0' to hdfs://192.168.137.100:9000/out 14/10/23 11:23:20 INFO mapred.LocalJobRunner: reduce > reduce 14/10/23 11:23:20 INFO mapred.Task: Task 'attempt_local1543091770_0001_r_000000_0' done. 14/10/23 11:23:20 INFO mapred.JobClient: map 100% reduce 100% 14/10/23 11:23:20 INFO mapred.JobClient: Job complete: job_local1543091770_0001 14/10/23 11:23:20 INFO mapred.JobClient: Counters: 19 14/10/23 11:23:20 INFO mapred.JobClient: File Output Format Counters 14/10/23 11:23:20 INFO mapred.JobClient: Bytes Written=252 14/10/23 11:23:20 INFO mapred.JobClient: File Input Format Counters 14/10/23 11:23:20 INFO mapred.JobClient: Bytes Read=292 14/10/23 11:23:20 INFO mapred.JobClient: FileSystemCounters 14/10/23 11:23:20 INFO mapred.JobClient: FILE_BYTES_READ=1416 14/10/23 11:23:20 INFO mapred.JobClient: HDFS_BYTES_READ=584 14/10/23 11:23:20 INFO mapred.JobClient: FILE_BYTES_WRITTEN=141536 14/10/23 11:23:20 INFO mapred.JobClient: HDFS_BYTES_WRITTEN=252 14/10/23 11:23:20 INFO mapred.JobClient: Map-Reduce Framework 14/10/23 11:23:20 INFO mapred.JobClient: Reduce input groups=19 14/10/23 11:23:20 INFO mapred.JobClient: Map output materialized bytes=1098 14/10/23 11:23:20 INFO mapred.JobClient: Combine output records=0 14/10/23 11:23:20 INFO mapred.JobClient: Map input records=42 14/10/23 11:23:20 INFO mapred.JobClient: Reduce shuffle bytes=0 14/10/23 11:23:20 INFO mapred.JobClient: Reduce output records=42 14/10/23 11:23:20 INFO mapred.JobClient: Spilled Records=84 14/10/23 11:23:20 INFO mapred.JobClient: Map output bytes=1008 14/10/23 11:23:20 INFO mapred.JobClient: Total committed heap usage (bytes)=456130560 14/10/23 11:23:20 INFO mapred.JobClient: SPLIT_RAW_BYTES=97 14/10/23 11:23:20 INFO mapred.JobClient: Map output records=42 14/10/23 11:23:20 INFO mapred.JobClient: Combine input records=0 14/10/23 11:23:20 INFO mapred.JobClient: Reduce input records=42 |
有多少reduce,就有多少输出文件,在eclipse中运行应该是在本地运行的,配置文件之类的都是用的本地,导致只有一个reduce.可以尝试,把集群配置文件复制到本地,一定复制全面,保证集群环境与本地环境一直,在看看效果。 至于集群中为什么19个,可以参考下面内容: MapReduce的大体流程是这样的,如图所示: 
由图片可以看到mapreduce执行下来主要包含这样几个步骤 1.首先对输入数据源进行切片 2.master调度worker执行map任务 3.worker读取输入源片段 4.worker执行map任务,将任务输出保存在本地 5.master调度worker执行reduce任务,reduce worker读取map任务的输出文件 6.执行reduce任务,将任务输出保存到HDFS |
 /2
/2 
Copyright © 2001-2024 About云-梭伦科技 Powered by Discuz! X3.4 Licensed Discuz Team.
简书 /
![]() 京ICP备2020039040号
京ICP备2020039040号
![]() 简书网举报电话:021-34700000
简书网举报电话:021-34700000