日志
Linux(ubuntu12.04)单节点伪分布一键安装CDH5.1.X及提交wordcount到yarn高可靠文档
|
问题导读:
1.如何安装CDH5?
2.如何安装Yarn?
3.如何验证是否安装成功?
4.运行wordcount,需要做哪些准备?

原文链接:http://www.aboutyun.com/thread-9405-1-1.html
本文源于:各个版本Linux单节点伪分布安装CDH5.1.X及提交wordcount到yarn高可靠文档,由于里面包含各种系统,所以这里单独拿出ubuntu12.04,让初学者更容易安装。
1.下载
| 系统版本 | 下载链接 |
Wheezy | |
Precise |
附件:
Precise
[attach]8011[/attach]
(这里选择的是Precise包)
Wheezy
[attach]8012[/attach]
2.复制到Linux操作系统
下载之后,我们使用wincp复制到Linux中

不会使用WinSCP,可以参考:
新手指导:使用 WinSCP(下载) 上文件到 Linux图文教程
3.安装package
sudo dpkg -i cdh5-repository_1.0_all.deb
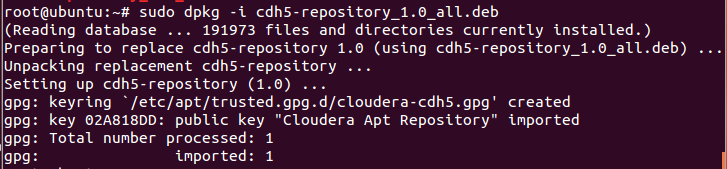
4.安装 CDH 5
curl -s http://archive.cloudera.com/cdh5/ubuntu/precise/amd64/cdh/archive.key | sudo apt-key add -
5.安装Yarn
sudo apt-get update
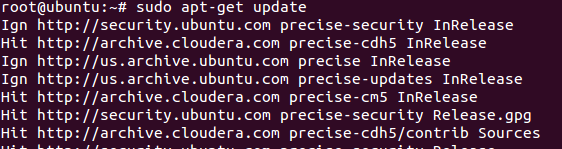
sudo apt-get install hadoop-conf-pseudo

6.启动hadoop,验证是否正常工作
Ubuntu 系统:
dpkg -L hadoop-conf-pseudo
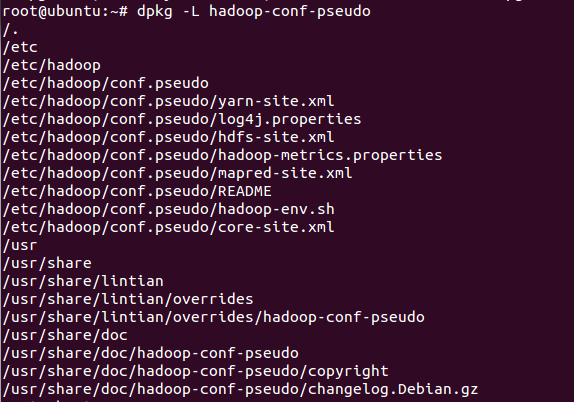
注意的是配置文件目录为: /etc/hadoop/conf.pseudo

hadoop相关组件配置在
/etc/hadoop/conf.
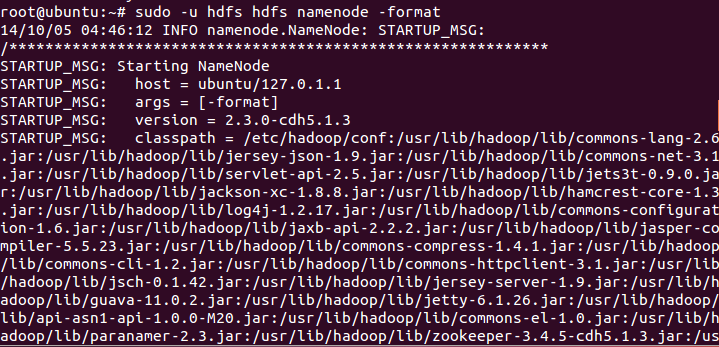
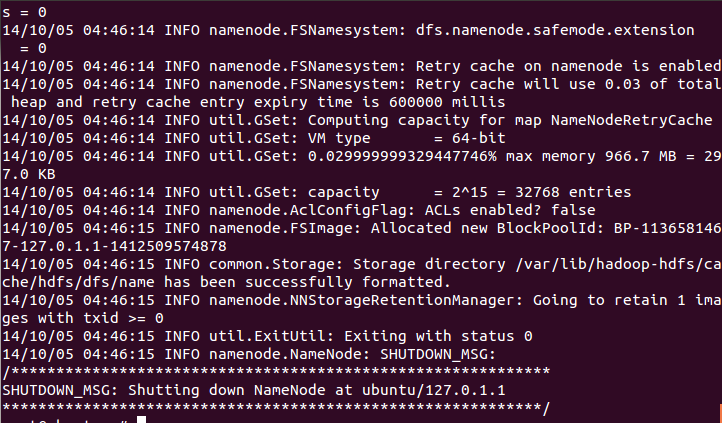
第一步:格式化namenode:
sudo -u hdfs hdfs namenode -format
注意
所有的命令都是sudo -u hdfs 下面,如果执行这个命令需要输入密码,则说明安装有问题
在安装过程中会自动格式化hdfs,但是这里必须执行这一步
第二步:启动hdfs
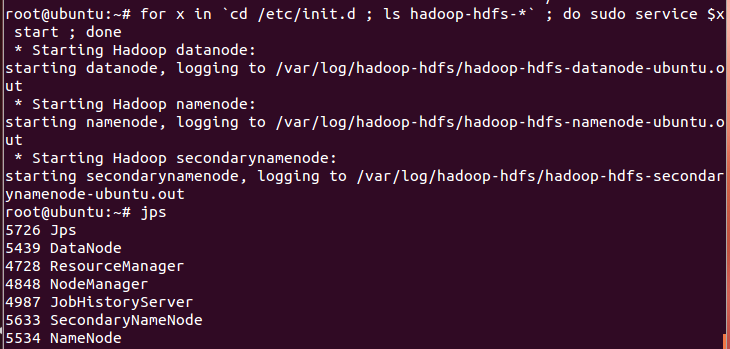
for x in `cd /etc/init.d ; ls hadoop-hdfs-*` ; do sudo service $x start ; done
第三步:创建 /tmp, Staging and Log 目录
1.如果存在旧的 /tmp则移除
sudo -u hdfs hadoop fs -rm -r /tmp
2.创建新目录并设置权限:
sudo -u hdfs hadoop fs -mkdir -p /tmp/hadoop-yarn/staging/history/done_intermediate
sudo -u hdfs hadoop fs -chown -R mapred:mapred /tmp/hadoop-yarn/staging
sudo -u hdfs hadoop fs -chmod -R 1777 /tmp
sudo -u hdfs hadoop fs -mkdir -p /var/log/hadoop-yarn
sudo -u hdfs hadoop fs -chown yarn:mapred /var/log/hadoop-yarn
第四步:检查核实创建文件
drwxrwxrwt - hdfs supergroup 0 2012-05-31 15:31 /tmp
drwxr-xr-x - hdfs supergroup 0 2012-05-31 15:31 /tmp/hadoop-yarn
drwxrwxrwt - mapred mapred 0 2012-05-31 15:31 /tmp/hadoop-yarn/staging
drwxr-xr-x - mapred mapred 0 2012-05-31 15:31 /tmp/hadoop-yarn/staging/history
drwxrwxrwt - mapred mapred 0 2012-05-31 15:31 /tmp/hadoop-yarn/staging/history/done_intermediate
drwxr-xr-x - hdfs supergroup 0 2012-05-31 15:31 /var
drwxr-xr-x - hdfs supergroup 0 2012-05-31 15:31 /var/log
drwxr-xr-x - yarn mapred 0 2012-05-31 15:31 /var/log/hadoop-yarn
第五步:启动 YARN
sudo service hadoop-yarn-resourcemanager start
sudo service hadoop-yarn-nodemanager start
sudo service hadoop-mapreduce-historyserver start
第六步:创建用户目录
sudo -u hdfs hadoop fs -mkdir /user/aboutyun
sudo -u hdfs hadoop fs -chown aboutyun/user/aboutyun
在yarn上运行wordcount
这里的运行用户为aboutyun
1.创建运行job用户目录
sudo -u hdfs hadoop fs -mkdir /user/aboutyun
sudo -u hdfs hadoop fs -chown aboutyun /user/aboutyun
2.切换aboutyun用户
[attach]8004[/attach]
记得这一步很重要,否则会创建目录错误
3.创建hdfs输入目录,并上传数据
hadoop fs -mkdir input
hadoop fs -put /etc/hadoop/conf/*.xml input
hadoop fs -ls input
Found 3 items:
-rw-r--r-- 1 joe supergroup 1348 2012-02-13 12:21 input/core-site.xml
-rw-r--r-- 1 joe supergroup 1913 2012-02-13 12:21 input/hdfs-site.xml
-rw-r--r-- 1 joe supergroup 1001 2012-02-13 12:21 input/mapred-site.xml
4.设置HADOOP_MAPRED_HOME (在aboutyun用户下)
export HADOOP_MAPRED_HOME=/usr/lib/hadoop-mapreduce
5.运行wordcount程序
hadoop jar /usr/lib/hadoop-mapreduce/hadoop-mapreduce-examples.jar grep input output23 'dfs[a-z.]+'


6.查看输出目录output23
hadoop fs -ls

7.列出输出文件
hadoop fs -ls output23
Found 2 items
-rw-r--r-- 1 aboutyun aboutyun 0 2014-10-05 05:45 output23/_SUCCESS
-rw-r--r-- 1 aboutyun aboutyun 244 2014-10-05 05:45 output23/part-r-00000

8.输出结果
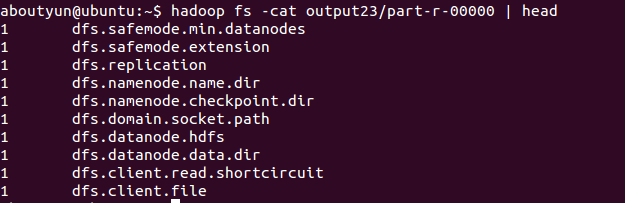
$ hadoop fs -cat output23/part-r-00000 | head
1 dfs.safemode.min.datanodes
1 dfs.safemode.extension
1 dfs.replication
1 dfs.permissions.enabled
1 dfs.namenode.name.dir
1 dfs.namenode.checkpoint.dir
1 dfs.datanode.data.dir





 /2
/2 