日志
实际生产面试案例分享
|
这里分享几个实际生产中,大家遇到的问题,以及解决办法。对于正在面试的成员,你可以思考,假如你遇到这样的问题,你该如何处理。如果你已经工作了,由于我们每个人所接触的场景都是有限的。对于下面案例也可以扩充下大家的知识面。
分享案例1:
公司有224台机器,内存单个384G,48core。在集群的使用中,经常遇到内存空闲。但是cpu使用很高。白白浪费了很多的内存。那么该如何调优最大限度使用内存。
解决办法:
该如何增大内存的使用,为何内存不能利用起来。
假如我们分配一个任务或则一个container。
那么这个container内存和core的比例是1:1,从这里面我们可以计算:
内存:core=1:1,那么core有48个,而内存只能分配48G。也就是只能有48个container,不能再多了,因为core已经分配完毕了。所以剩下了大量的内存没有是用。那么我们该如何使用让内存利用起来。
内存:core=8:1,这样每个container有一个core和8G内存使用,这样内存完全被利用起来,而且任务会非常的快。
当然上面只是理想情况,在实际使用中,我们可能会留一些内存,上面我们只需要知道,如何才能最大限度的使用集群资源,而不造成浪费或则使用集群的过程中,始终不知道为何会剩余这么多内存的原因。
分享案例2:
Oracle数据库中有3张表的数据,将oracle中的数据通过OGG发送到 kafka 对应的几个topic,我们想通过flink 去kafka中消费清洗对应的topic的数据,然后做join操作,最终将join后的数据写入到一张Hive表。
由于存在网络延迟, Oracle中的部分表的部分数据会延迟3~5天才到达Oracle数据库,导致部分表的数据join不上,需要在第二天手动去join前几天的数据然后写入hive表,这种方式,实效性较差,有没有某种方法可以做到每几个小时去join一下原来的数据,join上了就存到一张表,join不上的继续join。flink 或者spark 可以处理这种场景吗,或者这种场景有没有什么好的处理方法呢?
解决办法:
我们知道由于面试趋于考察面试者的能力,经常会出一些场景。上面就是一个很好的场景,而且确实是一个难题。
我们知道Flink和spark都有解决延迟数据的问题,或则乱序问题,但是Flink考虑了来的更晚的数据,这时候该怎么办?那就是侧输出,然后重新计算,可以解决上面问题
我们进一步来讲,这个侧输出到底如何实现,其实我们前面分享的Flink代码已经有了,大家可能没有注意,这里在贴出来sideOutputLateData(outputTag),附件中图也标了出来。
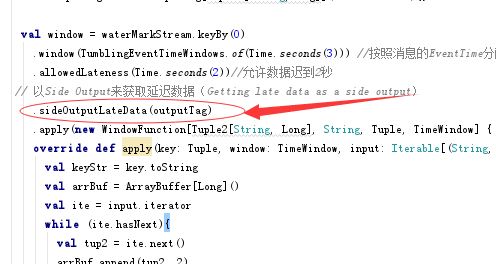
下面是整个代码。
更多代码大家到相关主题中下载源码:
https://t.zsxq.com/UrfiyZB
分享案例3:
这是咱们VIP成员遇到的问题。
MYSQL交易数据如何同步到Hive。
比如 用户借款表:字段{状态、逾期天数、利息等字段},
这些字段每天都会更新,因为一些特别的原因,可能还会删除一些记录。
如何将这些变化的数据同步到Hive中?使用什么工具或解决方案?
关系型数据中的 增删改 后的数据怎么同步到Hive 或 Hdfs中? 有增量同步解决方案吗?有实时同步文案吗?
解决方法:
对于MYSQL同步到Hive,我们第一反应想到的是Sqoop,但是这里面有个问题,他可以实时增量吗?他可以操作这么多表实时增加和删除吗?显然Sqoop使用起来会非常的不顺手。那么你会想到什么方案?
这时候我们需要想实时的框架有哪些?
Flink,Spark,storm。
因此为了实现如此复杂的业务,我们只能使用Flink或则Spark来实时讲操作传递到Hive中。这里Storm就不考虑了,当然为了保证数据的稳定性,我们还可以使用Kakfa等组件。
对于上面只是一种解决办法,如果大家发挥才智,相信有更好的办法,欢迎讨论
以上内容是在有时间的情况下经常帮助大家解决问题,会让我们收获非常多的内容。首先不说对别人的收获是什么,对自己本身收获是非常多的,不包括你所交的朋友,人脉等。技术知识最起码就能增长不少。这就是交流的作用。
在有能力的情况下,帮助别人就是帮助自己。
以上内容来自About云知识星球





 /2
/2 