日志
如何根据安装包自带wordcount例子,写相关mapredcue
问题导读
1.如何查看hadoop带自带例子源码?
2.本文使用的什么工具进行反编译?
3.hadoop2.7如何实例化job的?

原文连接:
1.如何查看hadoop带自带例子源码?
2.本文使用的什么工具进行反编译?
3.hadoop2.7如何实例化job的?
原文连接:
如何反编译hadoop2.x(2.7为例)安装包自带wordcount
我们在自己写wordcount的过程中,最烦恼的一个问题,api兼容问题。
从别的地方直接copy过来不能直接使用,那么如何变成我们自己的,该如何与当前版本兼容,我们是该使用job类,还是jobconf类; 是使用new job(,);还是使用job.getInstane()。
这里交给大家一个方法,就是反编译安装包自带的例子。
例子的路径:
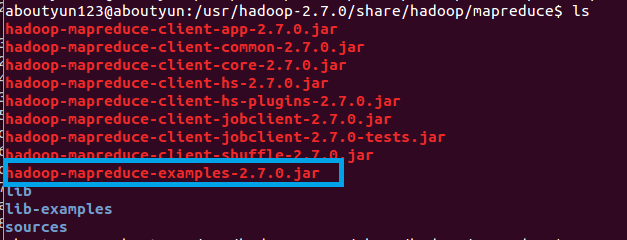
hadoop-2.7.0.tar.gz
链接:http://pan.baidu.com/s/1eQ1sUjS 密码:0h97
jar包下载:
hadoop-mapreduce-examples-2.7.0
链接:http://pan.baidu.com/s/1qWOdiEC 密码:qfrx
直接解压,看到下面内容:
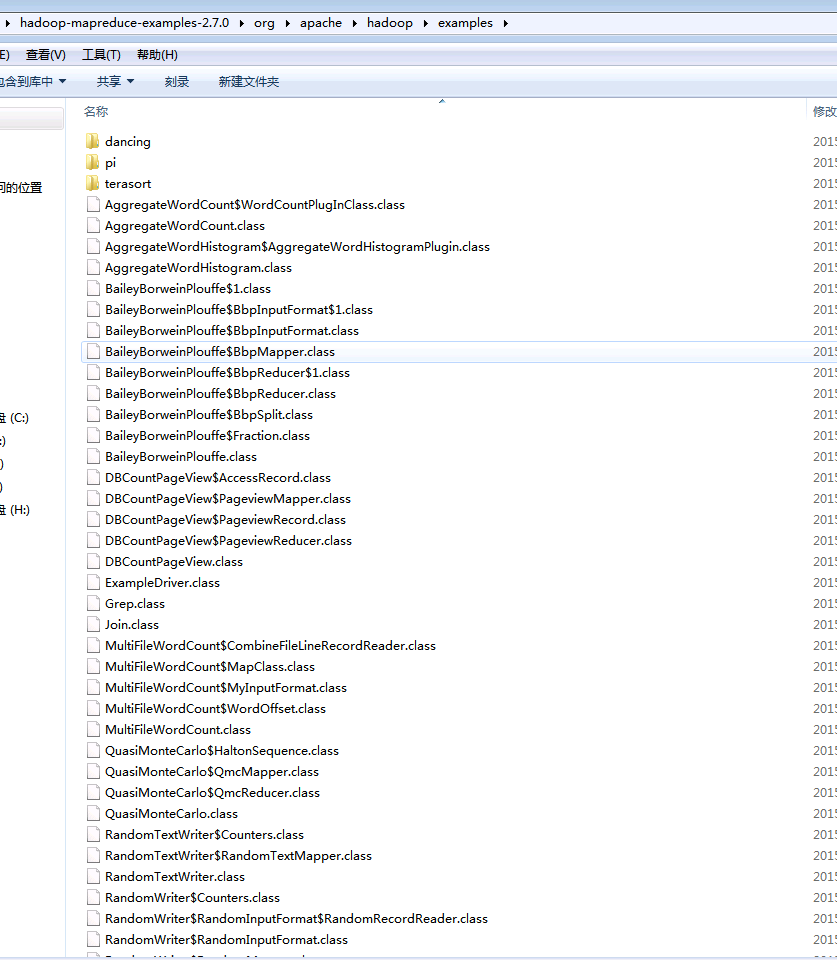
上面是编译的文件。我们该如何看到源码
我们下载jad
 jad.rar
jad.rar
下载,解压会看到jad.exe
将jad.exe放到jdk的bin目录下
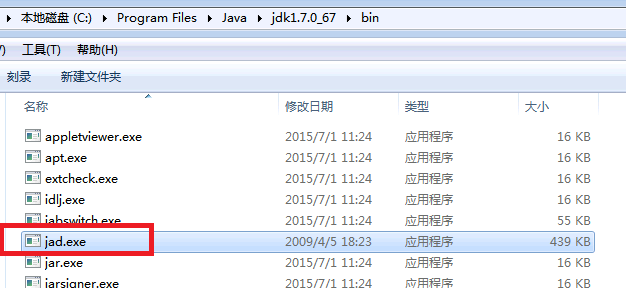
然后进入
通过cmd进入C:\Program Files\Java\jdk1.7.0_67\bin
执行命令:
C:\Program Files\Java\jdk1.7.0_67\bin>Jad -d D:\ -s wordcount.java -8 C:\Users\A
dministrator\Desktop\hadoop-mapreduce-examples-2.7.0\org\apache\hadoop\examples\
WordCount.class
上面命令有些复杂,简化:
Jad -d c:\test -s .java -8 HelloWorld.class
Jad -d 输出目录 -s 输出文件名 -8 被反翻译文件
最后文件在D:\找到
文件内容:
这时当我们写hadoop2.7 mapreduce就有了参考。当然你也可以参考hadoop2.7 API
我们在自己写wordcount的过程中,最烦恼的一个问题,api兼容问题。
从别的地方直接copy过来不能直接使用,那么如何变成我们自己的,该如何与当前版本兼容,我们是该使用job类,还是jobconf类; 是使用new job(,);还是使用job.getInstane()。
这里交给大家一个方法,就是反编译安装包自带的例子。
例子的路径:
[Bash shell] 纯文本查看 复制代码
1 | /usr/hadoop-2.7.0/share/hadoop/mapreduce |
hadoop-2.7.0.tar.gz
链接:http://pan.baidu.com/s/1eQ1sUjS 密码:0h97
jar包下载:
hadoop-mapreduce-examples-2.7.0
链接:http://pan.baidu.com/s/1qWOdiEC 密码:qfrx
直接解压,看到下面内容:
上面是编译的文件。我们该如何看到源码
我们下载jad
jad.rar 下载,解压会看到jad.exe
将jad.exe放到jdk的bin目录下
然后进入
通过cmd进入C:\Program Files\Java\jdk1.7.0_67\bin
执行命令:
C:\Program Files\Java\jdk1.7.0_67\bin>Jad -d D:\ -s wordcount.java -8 C:\Users\A
dministrator\Desktop\hadoop-mapreduce-examples-2.7.0\org\apache\hadoop\examples\
WordCount.class
上面命令有些复杂,简化:
Jad -d c:\test -s .java -8 HelloWorld.class
Jad -d 输出目录 -s 输出文件名 -8 被反翻译文件
最后文件在D:\找到
文件内容:
[Bash shell] 纯文本查看 复制代码
001 002 003 004 005 006 007 008 009 010 011 012 013 014 015 016 017 018 019 020 021 022 023 024 025 026 027 028 029 030 031 032 033 034 035 036 037 038 039 040 041 042 043 044 045 046 047 048 049 050 051 052 053 054 055 056 057 058 059 060 061 062 063 064 065 066 067 068 069 070 071 072 073 074 075 076 077 078 079 080 081 082 083 084 085 086 087 088 089 090 091 092 093 094 095 096 097 098 099 100 101 102 103 104 105 106 107 108 109 | // Decompiled by Jad v1.5.8e2. Copyright 2001 Pavel Kouznetsov.// Jad home page: [url=http://kpdus.tripod.com/jad.html]http://kpdus.tripod.com/jad.html[/url]// Decompiler options: packimports(3) ansi // Source File Name: WordCount.javapackage org.apache.hadoop.examples;import java.io.IOException;import java.io.PrintStream;import java.util.Iterator;import java.util.StringTokenizer;import org.apache.hadoop.conf.Configuration;import org.apache.hadoop.fs.Path;import org.apache.hadoop.io.IntWritable;import org.apache.hadoop.io.Text;import org.apache.hadoop.mapreduce.*;import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;import org.apache.hadoop.util.GenericOptionsParser;public class WordCount{ public static class IntSumReducer extends Reducer { public void reduce(Text key, Iterable values, org.apache.hadoop.mapreduce.Reducer.Context context) throws IOException, InterruptedException { int sum = 0; for(Iterator i$ = values.iterator(); i$.hasNext();) { IntWritable val = (IntWritable)i$.next(); sum += val.get(); } result.set(sum); context.write(key, result); } public volatile void reduce(Object x0, Iterable x1, org.apache.hadoop.mapreduce.Reducer.Context x2) throws IOException, InterruptedException { reduce((Text)x0, x1, x2); } private IntWritable result; public IntSumReducer() { result = new IntWritable(); } } public static class TokenizerMapper extends Mapper { public void map(Object key, Text value, org.apache.hadoop.mapreduce.Mapper.Context context) throws IOException, InterruptedException { for(StringTokenizer itr = new StringTokenizer(value.toString()); itr.hasMoreTokens(); context.write(word, one)) word.set(itr.nextToken()); } public volatile void map(Object x0, Object x1, org.apache.hadoop.mapreduce.Mapper.Context x2) throws IOException, InterruptedException { map(x0, (Text)x1, x2); } private static final IntWritable one = new IntWritable(1); private Text word; public TokenizerMapper() { word = new Text(); } } public WordCount() { } public static void main(String args[]) throws Exception { Configuration conf = new Configuration(); String otherArgs[] = (new GenericOptionsParser(conf, args)).getRemainingArgs(); if(otherArgs.length < 2) { System.err.println("Usage: wordcount <in> [<in>...] <out>"); System.exit(2); } Job job = Job.getInstance(conf, "word count"); job.setJarByClass(org/apache/hadoop/examples/WordCount); job.setMapperClass(org/apache/hadoop/examples/WordCount$TokenizerMapper); job.setCombinerClass(org/apache/hadoop/examples/WordCount$IntSumReducer); job.setReducerClass(org/apache/hadoop/examples/WordCount$IntSumReducer); job.setOutputKeyClass(org/apache/hadoop/io/Text); job.setOutputValueClass(org/apache/hadoop/io/IntWritable); for(int i = 0; i < otherArgs.length - 1; i++) FileInputFormat.addInputPath(job, new Path(otherArgs[i]));[/i] FileOutputFormat.setOutputPath(job, new Path(otherArgs[otherArgs.length - 1])); System.exit(job.waitForCompletion(true) ? 0 : 1); }} |
这时当我们写hadoop2.7 mapreduce就有了参考。当然你也可以参考hadoop2.7 API





 /2
/2 