上篇about云日志分析项目准备6-2补充:scala安装
http://www.aboutyun.com/forum.php?mod=viewthread&tid=20769
hadoop集群配置有各种中文文档,这里不是术的讲解,而是道的说明,也就是不是具体交给你怎么做,而是交给你方法。这里也算是对hadoop集群的安装的一个总结。
#########################
此文档是对此文about云日志分析项目准备6:Hadoop、Spark集群搭建的一个说明
hadoop集群安装准备
首先需要一些准备工作,
安装Java、ssh、下载hadoop。
########################
有哪些进程
准备工作完毕,我们就开始安装了,那么如何安装:自然是解压,然后各种配置。
安装之后,我们看到的进程
master会看到下面进程
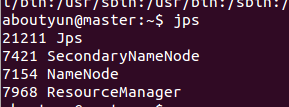
slave会看到下面进程

上面进程是否是固定的,无论你是ubuntu还是centos,还是其它系统,都是这些进程。
##############################################################
配置文件
hadoop配置有两种类型重要配置文件:
一种只读默认配置文件
core-default.xml, hdfs-default.xml, yarn-default.xml and mapred-default.xml.
一种Site-specific 配置文件
etc/hadoop/core-site.xml, etc/hadoop/hdfs-site.xml, etc/hadoop/yarn-site.xml and etc/hadoop/mapred-site.xml.
额外,你可以控制hadoop脚本,在bin/目录下,通过 etc/hadoop/hadoop-env.sh 和 etc/hadoop/yarn-env.sh.设置特定的值
HDFS 守护进程是 NameNode, SecondaryNameNode, and DataNode. YARN 守护进程是 ResourceManager, NodeManager, 和 WebAppProxy.如果使用MapReduce, 可以启用Job History Server.如果集群比较大,通常是在单独的主机上运行。
#########################################################
我们知道了各种配置文件,守护进程,那么剩下的就是对他们具体的配置。
core-site.xml配置说明
fs.defaultFS:这里是配置hdfs的访问路属性
值为:hdfs://master:8020
默认情况下,全路径是不写的。比如
全路径写法
- hadoop fs -ls hdfs://master:8020/
hadoop.tmp.dir:Hadoop的默认临时路径
配置的是本地路径,官网默认的是/tmp/hadoop-${user.name},这个路径下,由于Linux启动会删除,所以会造成,如果是datanode会添加或则启动失败,如果是namenode,重启后则需要重新格式化。
这里配置为:file:///home/aboutyun/hadoop/tmp
hadoop.proxyuser.$hostname.hosts:配置代理用户
hadoop.proxyuser.aboutyun.hosts:的含义abouyun用户可以代理任意机器上的用户
hadoop.proxyuser.aboutyun.groups:的含义abouyun用户代理任何组下的用户
更多参考:
hadoop代理用户 -超级用户代理其它用户
http://www.aboutyun.com/forum.php?mod=viewthread&tid=16507
io.file.buffer.size:是读写sequence文件的缓存区大小,作用:可以减少I/O次数。在大型集群上建议设置为65536 到 131072。
这里设置值为131072
hdfs-site.xml配置项说明
dfs.namenode.secondary.http-address:SNN的http服务地址和端口
这里配置为master:9001
dfs.namenode.name.dir:本地磁盘目录,NN存储fsimage文件的地方。可以是按逗号分隔的目录列表,fsimage文件会存储在全部目录,冗余安全。这里只设置了一个磁盘值为file:///home/aboutyun/hadoop/namenode
dfs.datanode.data.dir:本地磁盘目录,HDFS数据应该存储Block的地方。可以是逗号分隔的目录列表(典型的,每个目录在不同的磁盘)。
这里只设置了一个磁盘值为file:///home/aboutyun/hadoop/datanode
dfs.replication:数据块副本数。这里配置为3
dfs.webhdfs.enabled:在NN和DN上开启WebHDFS (REST API)功能。这里配置为true,也就是启用这个功能
mapred-site.xml配置说明
mapreduce.framework.name:使用框架运行mapreduce程序,这里配置为:yarn
mapreduce.jobhistory.address:MapReduce JobHistory Server地址。这里配置为master:10020
mapreduce.jobhistory.webapp.address:MapReduce JobHistory Server Web UI地址。这里配置为master:19888
可以在mapreduce.jobhistory.webapp.address参数配置的主机上对Hadoop历史作业情况经行查看。
关于jobhistory可查看
Hadoop jobhistory历史服务器介绍
http://www.aboutyun.com/forum.php?mod=viewthread&tid=8150
yarn-site.xml配置说明
yarn.nodemanager.aux-services:NodeManager上运行的附属服务。需配置成mapreduce_shuffle,才可运行MapReduce程序。这里配置为mapreduce_shuffle
yarn.nodemanager.aux-services.mapreduce.shuffle.class:shuffle类指定为org.apache.hadoop.mapred.ShuffleHandler。没有找到明确的定义,猜测这个类是可以自定义的。org.apache.hadoop.mapred.ShuffleHandler为系统提供
上门参数为了能够运行MapReduce程序,需要让各个NodeManager在启动时加载shuffle server,shuffle server实际上是Jetty/Netty Server,Reduce Task通过该server从各个NodeManager上远程拷贝Map Task产生的中间结果。上面增加的两个配置均用于指定shuffle serve。
yarn.resourcemanager.address:客户端访问ResourceManager 的地址。客户端通过该地址向RM提交应用程序,杀死应用程序等。配置值为:master:8032
yarn.resourcemanager.scheduler.address:ApplicationMaster通过该地址向RM申请资源、释放资源等。ResourceManager 对ApplicationMaster暴露的访问地址。这里配置为master:8030
yarn.resourcemanager.resource-tracker.address:NodeManager通过该地址向RM汇报心跳,领取任务等。ResourceManager 对NodeManager暴露(访问)的地址.这里配置为master:8031
yarn.resourcemanager.admin.address:管理员通过该地址向RM发送管理命令等。ResourceManager 对管理员暴露的访问地址。这里配置为master:8033
yarn.resourcemanager.webapp.address :用户可通过该地址在浏览器中查看集群各类信息。ResourceManager对外web ui地址。
|

 /2
/2 

 提升卡
提升卡 置顶卡
置顶卡 沉默卡
沉默卡 喧嚣卡
喧嚣卡 变色卡
变色卡 千斤顶
千斤顶 显身卡
显身卡



