| 非常感谢,我全部放进去搞定了 |
jxlxxxmz 发表于 2017-7-28 19:04 
如果不熟悉建议把lib下面的都放到里面。而且是spark与hadoop编译的。 |
nextuser 发表于 2017-7-28 14:24 部署了一个集群,三台机子,spark hadoop都在上面,其实都正常着呢,我再试试写个简单的spark程序好了,还是十分感谢!! |
本帖最后由 pig2 于 2017-8-2 13:53 编辑 jxlxxxmz 发表于 2017-7-28 10:18 spark应该都有对应的hadoop。而且spark与hadoop是需要编译的。 楼主的spark是单独部署的吗? 还有另外一个办法就是先写一个简单的spark程序。看看是否同样的问题。 |
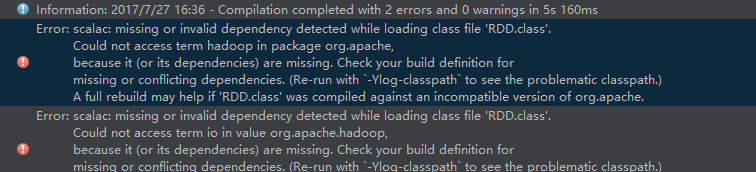
nextuser 发表于 2017-7-27 19:25 没有hadoop,需要用hadoop包么?找不到rdd,应该spark核心包的东西,那我加一下试试 |
xiaobaiyang 发表于 2017-7-28 08:37 主要是编译找不到rdd。其实我也可以加一个【*】,这个我是知道的,就是不知道是版本的问题还是什么,报错找不到依赖。 |
| 程序应该有个小问题,就是设置master为本地模式的时候,应该是local[n],n>=2,比如local[2] |
本帖最后由 nextuser 于 2017-7-27 19:30 编辑 jxlxxxmz 发表于 2017-7-27 19:05 Spark 2.2.0 使用的Scala 2.11. spark 2.1不清楚。里面有hadoop包吗? |
yuwenge 发表于 2017-7-27 18:45 这个帖子我看了,里边的spark版本是1.6的,我这个是2.1的,比较新,会不会是与scala2.11不匹配? spark的包我导入了,spark的核心包core,其他应该都不需要。 |
 /2
/2 
Copyright © 2001-2024 About云-梭伦科技 Powered by Discuz! X3.4 Licensed Discuz Team.
简书 /
![]() 京ICP备2020039040号
京ICP备2020039040号
![]() 简书网举报电话:021-34700000
简书网举报电话:021-34700000