问题导读
1.添加开发包有几种方式?
2.使用sbt可能存在什么问题?
3.spark streaming开发需要了解哪些开发知识?

相关篇章
spark开发环境详细教程1:IntelliJ IDEA使用详细说明
http://www.aboutyun.com/forum.php?mod=viewthread&tid=22320
spark开发环境详细教程2:window下sbt库的设置
http://www.aboutyun.com/forum.php?mod=viewthread&tid=22409
spark开发环境详细教程3:IntelliJ IDEA创建项目
http://www.aboutyun.com/forum.php?mod=viewthread&tid=22410
创建spark应用程序,我们需要具体一定的编程知识。在写程序的时候,我们需要导入相关包。编写hbase,需要导入hbase包,写storm需要导入storm包。同样spark streaming包,需要导入spark streaming包。这样我们不至于写一个wordcount,不会从底层写起。否则就太麻烦了。
导入包,后面我们需要了解下StreamingContext。为了初始化Spark Streaming程序,一个StreamingContext对象必需被创建,它是Spark Streaming所有流操作的主要入口。一个StreamingContext 对象可以用SparkConf对象创建。StreamingContext这里可能不理解,其实跟SparkContext也差不多的。(可参考让你真正理解什么是SparkContext, SQLContext 和HiveContext)。同理也有hadoop Context,它们都是全文对象,并且会获取配置文件信息。那么配置文件有哪些?比如hadoop的core-site.xml,hdfs-site.xml等,spark如spark-defaults.conf等。这时候我们可能对StreamingContext有了一定的认识。
更多可参考
让你真正明白spark streaming
http://www.aboutyun.com/forum.php?mod=viewthread&tid=21141
具备上面的知识,我们在看下面的例子。
操作的流程:
1.在Linux上输入
[mw_shl_code=bash,true]nc -lk 9999[/mw_shl_code]
Linux ip地址:192.168.1.10
2.运行下面程序。
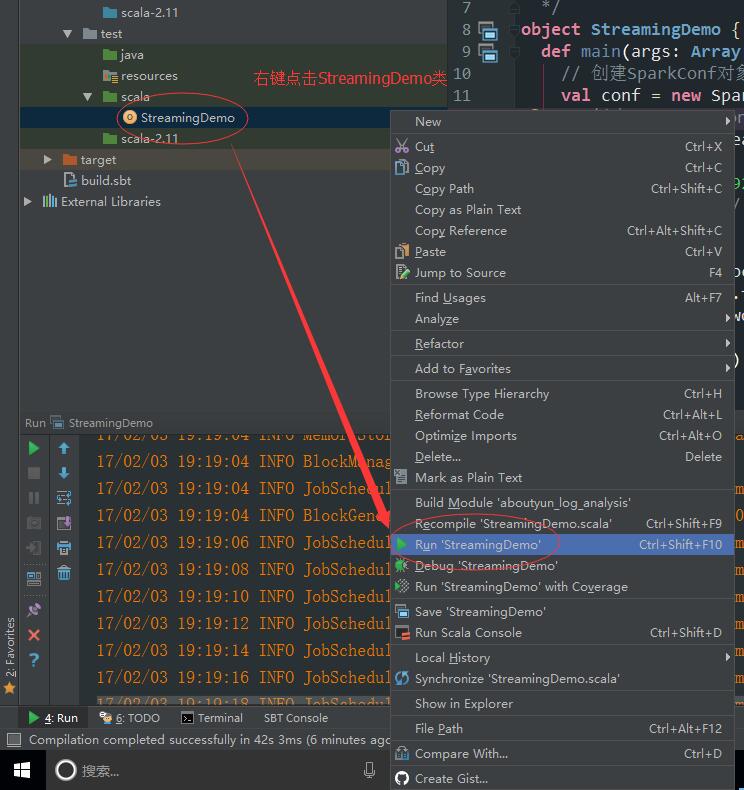
[mw_shl_code=scala,true]/**
* Created by aboutyun on 2017/8/2.
*/
import org.apache.spark.SparkConf
import org.apache.spark.storage.StorageLevel
import org.apache.spark.streaming.{Seconds, StreamingContext}
object StreamingDemo {
def main(args: Array[String]): Unit = {
// 创建SparkConf对象,并指定AppName和Master
val conf = new SparkConf().setAppName("StreamingDemo").setMaster("local")
// 创建StreamingContext对象
val ssc = new StreamingContext(conf, Seconds(10))
val hostname = "192.168.1.10" // 即我们的master虚拟机
val port = 9999 // 端口号
// 创建DStream对象
val lines = ssc.socketTextStream(hostname, port, StorageLevel.MEMORY_AND_DISK_SER)
val words = lines.flatMap(_.split(" "))
val wordCounts = words.map(x => (x, 1)).reduceByKey(_ + _)
wordCounts.print()
ssc.start()
ssc.awaitTermination()
}
}
[/mw_shl_code]
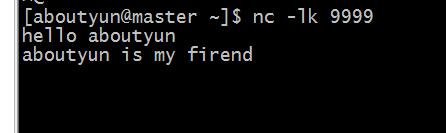
然后在Linux下输入一些字符串。
[mw_shl_code=bash,true]hello aboutyun
aboutyun is my firend[/mw_shl_code]
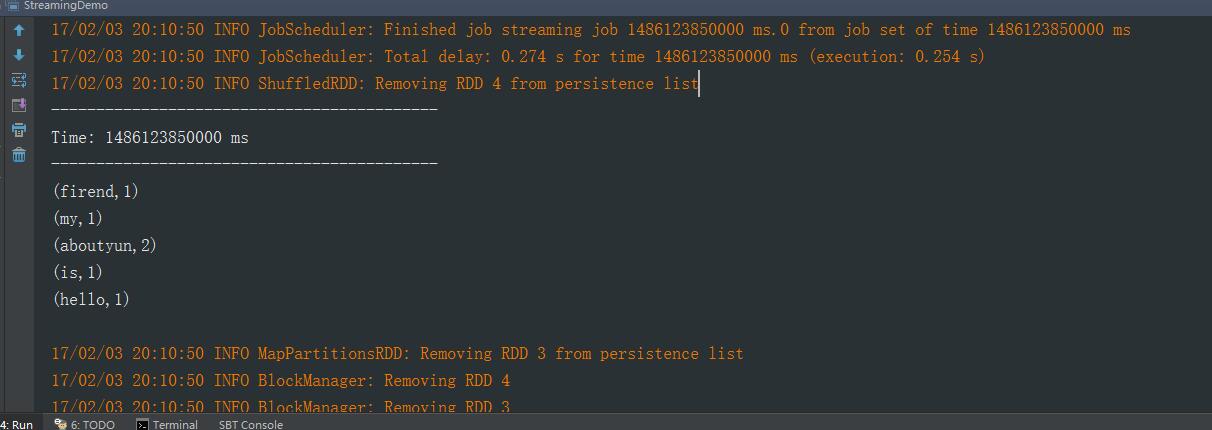
然后查看Intellij Idea的控制台:
########################
对于第三篇如果了解不多,不知道怎么将代码放到环境中。
创建项目
创建项目。
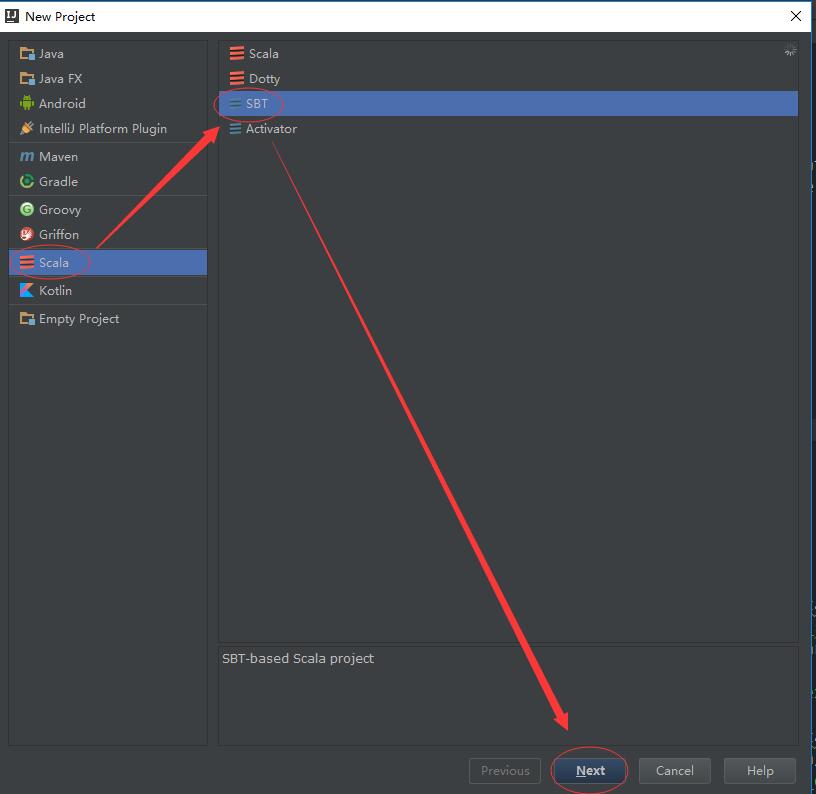
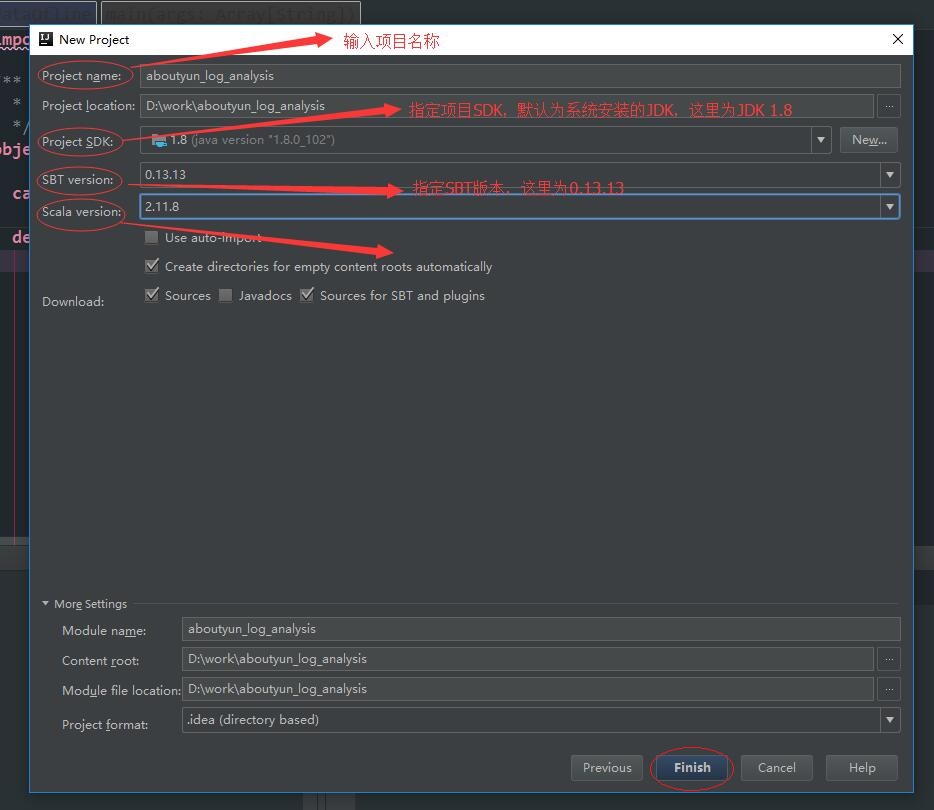
点击完 “Finish”按钮后,Intellij Idea会进行该项目的构建,这个过程需要一定的时间,因为sbt需要下载指定scala版本(在这里是scala 2.11.8)的基础依赖包。下载过程如下:

注意:如果下载不成功的话,需要考虑翻墙
项目构建完成后的目录结构如下所示:

添加依赖
由于我们编写的是 Spark Streaming 程序,所以还需要添加相关的依赖。其实就是编写build.sbt文件。我们可以先查看下现有的build.sbt文件内容:
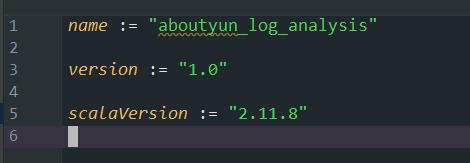
然后将以下依赖加入(注意空格):
[mw_shl_code=bash,true]libraryDependencies += "org.apache.spark" % "spark-streaming_2.11" % "1.6.3"
libraryDependencies += "org.apache.spark" % "spark-streaming-kafka_2.11" % "1.6.3"[/mw_shl_code]
加好后如下所示:
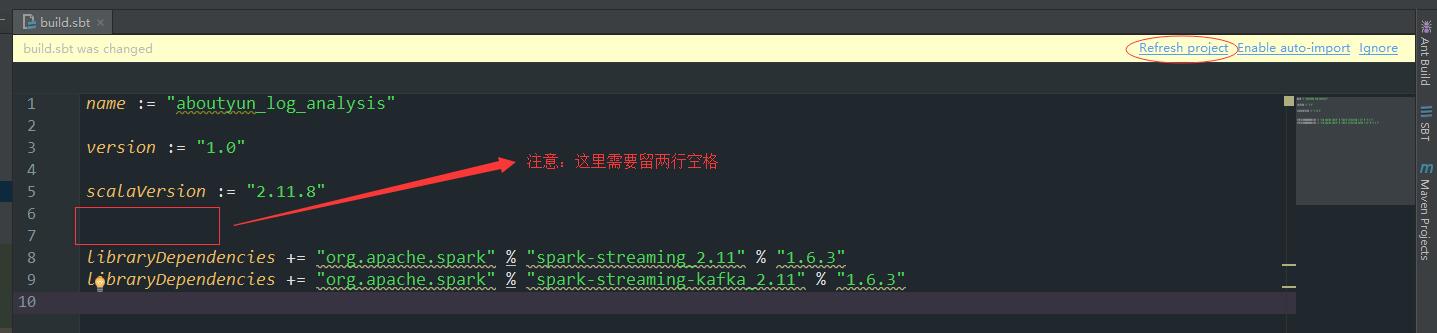
点击“Refresh project”,Intellij Idea会通过SBT下载这些写好的依赖,这个过程也会花费很长的时间。
编写程序
目前创建了aboutyun_log_analysis工程,工程中包含了aboutyun_log_analysis/src/main/ 和 aboutyun_log_analysis/src/test/ 目录,其中前者是用于生产环境中代码编写,后者用于测试代码编写。本文将在后者目录进行代码编写。
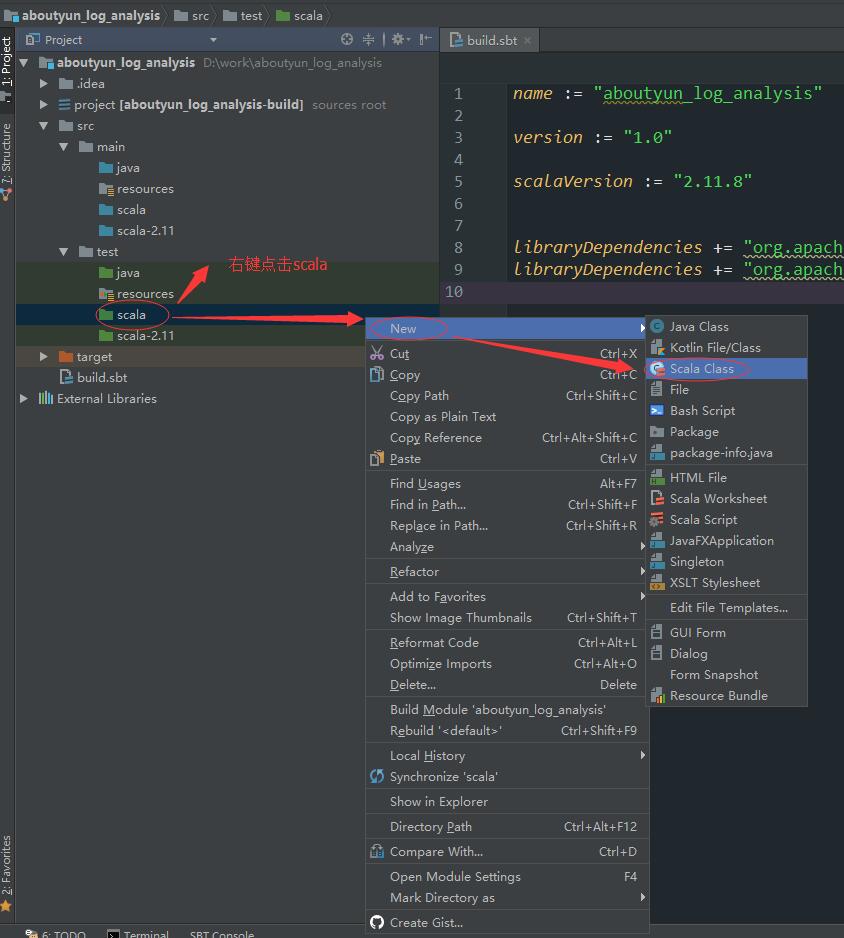
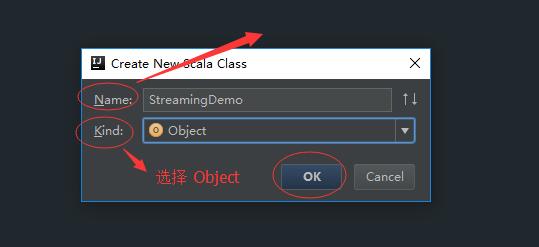
这样我们就创建了一个StreamingDemo类。接下来可以将代码放到环境里。
补充【重要】:
由于sbt,可能会下载失败。可通过添加本地库。这样就不需要添加依赖了。
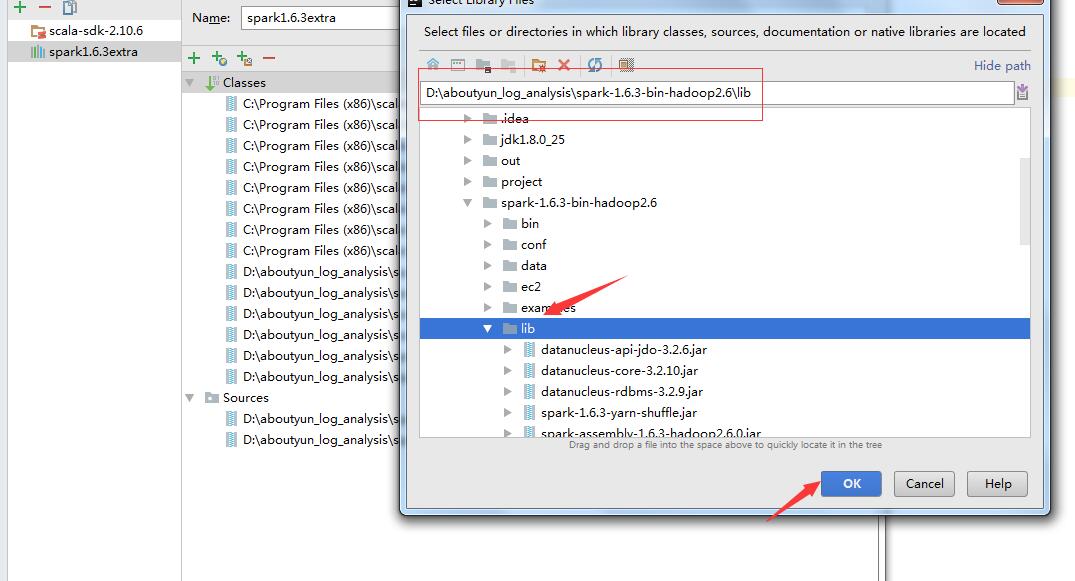
详细可参考第三篇
spark开发环境详细教程3:IntelliJ IDEA创建项目
http://www.aboutyun.com/forum.php?mod=viewthread&tid=22410
问题答案:
1.添加开发包有几种方式?
有两种可以使用sbt,也可以添加本地库
2.使用sbt可能存在什么问题?
由于网络原因,经常下载失败
3.spark streaming开发需要了解哪些开发知识?
1.首先需要导入相关包
2.需要了解streaming context
|


 /2
/2 

 提升卡
提升卡 置顶卡
置顶卡 沉默卡
沉默卡 喧嚣卡
喧嚣卡 变色卡
变色卡 千斤顶
千斤顶 显身卡
显身卡




