package com.it.hbase;
import java.text.SimpleDateFormat;
import java.util.Date;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.hbase.client.Put;
import org.apache.hadoop.hbase.mapreduce.TableOutputFormat;
import org.apache.hadoop.hbase.mapreduce.TableReducer;
import org.apache.hadoop.hbase.util.Bytes;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Counter;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
/**
* 将数据批量的导入到HBase中(HDFS)
* @author hanyueyue
*
*/
public class BatchImport {
public static void main(String[] args) throws Exception {
final Configuration configuration = new Configuration();
//设置zookeeper 的代理节点
configuration.set("hbase.zookeeper.quorum", "hadoop");
//设置hbase表名称
configuration.set(TableOutputFormat.OUTPUT_TABLE, "wlan_log");
//将该值改大,防止hbase超时退出
configuration.set("dfs.socket.timeout", "180000");
final Job job = new Job(configuration, "HBaseBatchImport");
job.setMapperClass(BatchImportMapper.class);
job.setReducerClass(BatchImportReducer.class);
//设置map的输出,不设置reduce的输出类型 reduce没有输出
job.setMapOutputKeyClass(LongWritable.class);
job.setMapOutputValueClass(Text.class);
//设置输入路径
FileInputFormat.setInputPaths(job, "hdfs://hadoop:9000/http.dat");
job.setInputFormatClass(TextInputFormat.class);
//不再设置输出路径,而是设置输出格式类型
job.setOutputFormatClass(TableOutputFormat.class);
job.waitForCompletion(true);
}
static class BatchImportMapper extends Mapper<LongWritable, Text, LongWritable, Text>{
SimpleDateFormat dateformat1=new SimpleDateFormat("yyyyMMddHHmmss");
Text v2 = new Text();
protected void map(LongWritable key, Text value, Context context) throws java.io.IOException ,InterruptedException {
final String[] splited = value.toString().split("\t");
try {
final Date date = new Date(Long.parseLong(splited[0].trim()));
final String dateFormat = dateformat1.format(date);
String rowKey = splited[1]+":"+dateFormat;//手机号+时间 行键格式
v2.set(rowKey+"\t"+value.toString());
context.write(key, v2);
} catch (NumberFormatException e) {
Counter counter = context.getCounter("BatchImport", "ErrorFormat");
counter.increment(1L);
System.out.println("出错了"+splited[0]+" "+e.getMessage());
}
};
}
static class BatchImportReducer extends TableReducer<LongWritable, Text, NullWritable>{
protected void reduce(LongWritable key, java.lang.Iterable<Text> values, Context context) throws java.io.IOException ,InterruptedException {
for (Text text : values) {
String[] splited = text.toString().split("\t");
//设置行键
Put put = new Put(Bytes.toBytes(splited[0]));
//列族名称,列名称,值 插入数据
put.add(Bytes.toBytes("cf"), Bytes.toBytes("date"), Bytes.toBytes(splited[1]));
put.add(Bytes.toBytes("cf"), Bytes.toBytes("msisdn"), Bytes.toBytes(splited[2]));
put.add(Bytes.toBytes("cf"), Bytes.toBytes("apmac"), Bytes.toBytes(splited[3]));
put.add(Bytes.toBytes("cf"), Bytes.toBytes("acmac"), Bytes.toBytes(splited[4]));
//省略其他字段,调用put.add(....)即可
context.write(NullWritable.get(), put);//写入
}
};
}
}
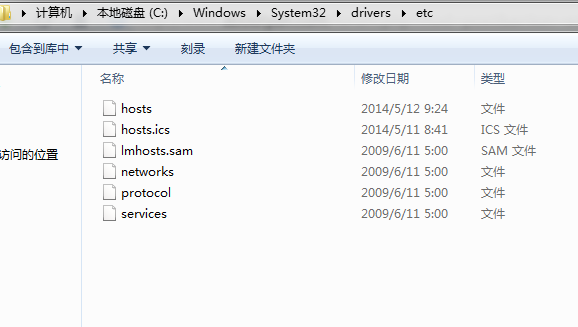
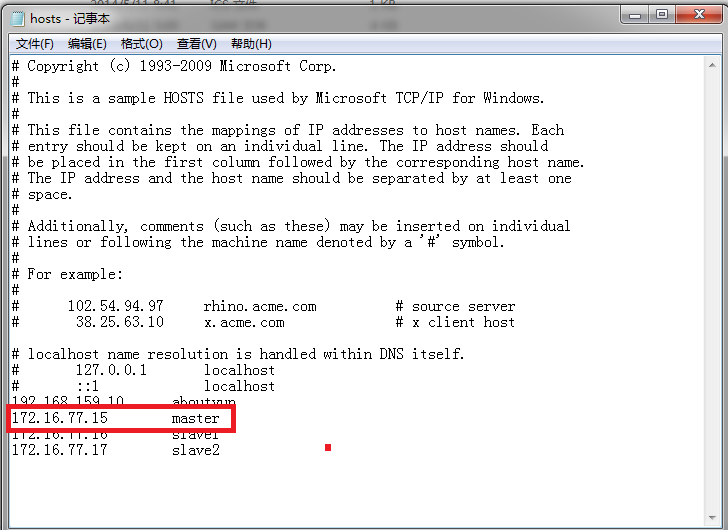
Exception in thread "main" java.net.UnknownHostException: unknown host: hadoop
at org.apache.hadoop.ipc.Client$Connection.<init>(Client.java:214)
at org.apache.hadoop.ipc.Client.getConnection(Client.java:1196)
at org.apache.hadoop.ipc.Client.call(Client.java:1050)
at org.apache.hadoop.ipc.RPC$Invoker.invoke(RPC.java:225)
at $Proxy1.getProtocolVersion(Unknown Source)
at org.apache.hadoop.ipc.RPC.getProxy(RPC.java:396)
at org.apache.hadoop.ipc.RPC.getProxy(RPC.java:379)
at org.apache.hadoop.hdfs.DFSClient.createRPCNamenode(DFSClient.java:119)
at org.apache.hadoop.hdfs.DFSClient.<init>(DFSClient.java:238)
at org.apache.hadoop.hdfs.DFSClient.<init>(DFSClient.java:203)
at org.apache.hadoop.hdfs.DistributedFileSystem.initialize(DistributedFileSystem.java:89)
at org.apache.hadoop.fs.FileSystem.createFileSystem(FileSystem.java:1386)
at org.apache.hadoop.fs.FileSystem.access$200(FileSystem.java:66)
at org.apache.hadoop.fs.FileSystem$Cache.get(FileSystem.java:1404)
at org.apache.hadoop.fs.FileSystem.get(FileSystem.java:254)
at org.apache.hadoop.fs.Path.getFileSystem(Path.java:187)
at org.apache.hadoop.mapreduce.lib.input.FileInputFormat.setInputPaths(FileInputFormat.java:352)
at org.apache.hadoop.mapreduce.lib.input.FileInputFormat.setInputPaths(FileInputFormat.java:321)
at com.it.hbase.BatchImport.main(BatchImport.java:45)
|

 /2
/2 

 提升卡
提升卡 置顶卡
置顶卡 沉默卡
沉默卡 喧嚣卡
喧嚣卡 变色卡
变色卡 千斤顶
千斤顶 显身卡
显身卡